{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
分散存储油气生产动态大数据的优化管理与快速查询
[王洪亮1  , 穆龙新
, 穆龙新1 , 时付更1 , 刘凯铭2 , 钱育蓉2 ]
, 穆龙新|
|


第一作者简介:王洪亮(1984-),男,黑龙江哈尔滨人,中国石油勘探开发研究院在读博士研究生,主要从事统计建模、油气领域大数据与人工智能研究。地址:北京市海淀区学院路20号,中国石油勘探开发研究院计算机应用技术研究所,邮政编码:100083。E-mail: whldqpi@126.com
利用大数据分布式存储与并行计算、数据仓库建模等技术构建多维分析引擎数据管理平台,实现了分散存储油气生产动态大数据的优化管理与快速查询,该系统可集中管理36×104余口油、气、水井的生产数据,并实现秒级响应。建立了油、气、水井生产多维分析主题模型,对数据进行预处理,在中国石油天然气集团有限公司层级实现了油区生产运行跟踪、重点油田生产预警、低产井和长停井现状、分类油藏开发规律等分析应用的快速、高效响应,处理时间由原来的1 d缩短到现在的5 s;油气生产模式分析基本单元由原来的油田细化为单井,生产管理更为细致;分析结果可以按照集团公司、油气田公司、油气田、区块、单井逐级追溯,实时掌握各基本单元的油气生产动态。
The multidimensional analysis engine data management platform is constructed using big data distributed storage and parallel computing, data warehouse modeling technology, realizing the optimal management and instant query of distributed oil and gas production dynamic big data. The centralized management and quick response of the production data of more than 36×104 oil, gas and water wells is realized. Multidimensional analysis subject model of oil, gas and water well production is built to pretreat the relevant data. At the level of China National Petroleum Corporation (CNPC), the rapid analysis and applications such as oil and gas production tracking, early production warning of key oilfields, analysis of low production wells and long shutdown wells, classification of reservoir development laws have been realized, and the processing time has been shortened from 1 d to 5 s. The basic unit of oil and gas production analysis is refined from oilfield to single well, making the production management more detailed. The process can be traced step by step according to CNPC, oil field company, field, block and single well, and the oil and gas production performance of each unit can be mastered in real time.
中国石油油气水井生产数据管理系统(简称A2系统)是中国石油天然气集团有限公司(以下简称“ 集团公司” )的大型信息系统之一。A2系统以油气生产管理为核心, 实现了油、气、水井生产数据的采集、处理、统计、汇总、存储、上报、发布等一体化管理。A2系统管理了36× 104余口油、气、水井的生产数据, 生产历史近60年, 数据记录超过60× 108条, 结构化数据量超过5 TB, 并发用户4 000多户。由于生产数据量巨大、并发高和系统建设时技术所限, 系统采用分散式部署, 即16个油气田公司各自部署一套系统, 管理着本油气田公司的油、气、水井生产数据, 共计16套数据库。A2系统采用关系型数据库, 数据模型采用面向对象模型进行设计。A2系统主要包含基础信息、生产测试、油气生产、增产措施、采油工艺(井设备)、油气集输(站库)6类数据, 共计362张数据表, 9 512个数据项。A2系统已经成为各油气田公司油气生产管理的日常工作平台, 取得了显著的应用效果。
集团公司在进行全局性油、气、水井生产分析时, 由于数据量巨大, 暴露出A2系统查询效率低、多个数据库间存在信息孤岛、人工收集数据时间长等问题:①系统采用关系型数据库, 数据表中数据记录超过1.0× 107条时, 在多表联合查询时, 查询时间超过5 min, 分析人员等待时间长; ②系统间存在信息孤岛问题, 不能互联互通, 人工收集数据时间长。在集团公司层级进行油、气、水井生产数据分析研究时, 需要重复登录16套系统收集数据, 再进行手工统计分析, 存在重复劳动, 不能高效进行全局分析。因此, 迫切需要一个能够实时掌握全局性油、气、水井生产动态的系统, 通过该系统可以深入透视分析数据背后潜在的有用信息, 支撑油气生产与研究工作。
国外大数据分析挖掘技术在石油工业中得到初步应用。将油气大数据作为资产, 基于数据驱动模型优化油气的勘探与生产, 降低石油公司生产成本[1, 2]。雪佛龙公司使用Hadoop技术进行地震数据分析来识别储集层[3]。与此同时, 中国油气行业对大数据技术的研究与应用也在持续深入推进。中国石油天然气集团有限公司已建成约70个大型信息系统并上线运行, 并正在推进智能油田建设[4]。鲁帅帅[5]基于大数据环境建立油气钻井信息分布式数据仓库; 曲海旭[6]利用大数据技术进行油田生产经营优化; 大数据与人工智能结合, 在智能钻井方案优化、测井曲线生成、水平井地质建模等方面的研究也取得了一定进展[7, 8, 9, 10]。
为解决集团公司在进行全局性油、气、水井生产动态分析时遇到的数据库查询分析效率低、多个数据库间存在信息孤岛、人工收集数据时间长等问题, 利用大数据分布式存储与并行计算、数据仓库建模等技术构建多维分析引擎数据管理平台, 实现一个系统管理36× 104余口油、气、水井生产数据, 同时实现快速查询与多维统计分析。
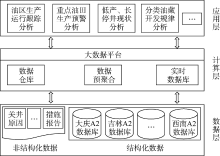
由于单机部署服务器的处理能力有限, 当业务增长到一定程度的时候, 单机的硬件资源将无法满足业务需求[11, 12, 13]。考虑油、气、水井生产数据总量巨大、增长速度快、计算机性能扩展与成本等方面的原因, 本文选用Hadoop的分布式文件存储系统(HDFS)和并行计算框架(MapReduce)作为本系统的基础支撑架构。利用Hadoop大数据平台, 结合分布式数据仓库(Hive)、多维分析引擎(Apache Kylin)、分布式实时数据仓库(HBase)等技术构建油气生产多维分析系统(见图1)。采用多维分析技术保证秒级响应, 实现36× 104余口油、气、水井生产大数据的集中存储与管理; 基于油、气、水井全样本数据分析, 开展油区生产运行跟踪、重点油田生产预警、低产井和长停井现状、分类油藏开发规律等分析研究工作; 在集团公司层级进行统一的生产多维分析, 并实现集团公司、油气田公司、油气田、区块、单井信息的逐级追溯, 满足实时掌握油气生产动态的需求。
 | 图1 油气生产多维分析架构图 |
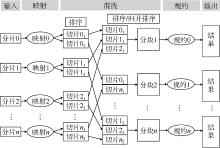
1.2.1 MapReduce并行计算框架
MapReduce是一种并行计算框架, 适用于大规模数据集的并行运算[14, 15, 16, 17, 18, 19]。它的设计思想是将一个大的计算任务分为多个小的任务, 然后把这些小的任务分配到各个工作节点进行计算, 每个子节点完成自己的计算任务后, 把各个子节点的结果进行聚合操作, 从而算出最后的结果(见图2)。
 | 图2 并行计算过程 |
1.2.2 Hive数据仓库
Hive是基于HDFS和MapReduce实现的, 是一种构建于Hadoop平台上的数据仓库[20, 21, 22]。Hive的设计思想是应用简单的类SQL(结构化查询语言)来取代复杂的MapReduce编程过程, 从而让业务人员熟练使用。
Hive给用户提供访问数据仓库的手段, 通过客户端提供的指令, 控制台检索数据仓库中的数据; Hive同时也提供应用程序接口进行访问查询。
Hive数据仓库的服务端和客户端之间的通信方式基于Thrift框架实现。通信框架也负责把客户端的类SQL语句发送给Driver解析器并同时返回解析器的处理结果。
1.2.3 Kylin多维分析引擎
Apache Kylin是一个开源的分布式多维分析计算引擎。Kylin是联机分析技术(OLAP)在Hadoop上的一个应用实例, 可以提供基于HDFS多维数据的分析能力, 本身数据处理计算的能力已经达到PB(1× 250字节)级别, 能够在亚秒范围内查询数据仓库中的信息。
Kylin设计的基本思想是多维数据的预计算, 以存储空间来换取查询响应时间[23]。Kylin本身并不存储实际数据, 数据都存储在HDFS上。该引擎使用数据仓库中的数据作为其数据输入源, 当一批数据进入后, 它会计算出高维数据所有维度组合下的数据, 并将预计算完成后的数据存储在数据立方体中, 最后以键值对的方式存储在HBase数据库中。当操作人员进行数据访问时, 查询服务就会转换成HBase数据库上的扫描过程, 免除多表连接、聚合运算等高耗时的计算任务, 提高查询响应速度。
1.2.4 HBase实时查询数据库
HBase是基于列式存储的非关系型数据库, 解决了HDFS随机读写访问延时大的问题, 其本身具备了HDFS的高容错特点, 适合用于大数据的实时查询服务。
HBase作为NoSQL(非关系型数据库)存储系统, 本身可以存储结构化和非结构化的数据。HBase提供了简单的数据库操作方式。数据类型只有字符串一种类型, 并且存储表格可以设计得很大, 行数可达1.0× 108以上, 列数可达1.0× 106以上[24]。
根据总体设计, 技术实现主要包括数据仓库建模、数据采集、多维分析和可视化4个步骤。
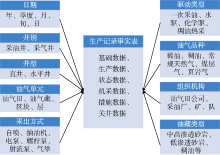
油气生产大数据多维分析主要包括油区生产运行跟踪、重点油田生产预警、低产井和长停井现状、分类油藏开发规律分析等主题(见表1)。每个主题的数据都是多维的, 需要从不同的角度进行分析。本文以油区生产运行跟踪分析主题的采出井生产数据分析为例, 介绍Hive数据仓库的建模过程。
| 表1 油气生产多维分析主题表 |
采出井生产数据分析主要研究采出井及油气生产单元的生产运行情况, 它涵盖的数据包括采出井基础数据、采出井生产数据、采出井状态数据、采出井措施数据、采出井机采数据、关井数据等。
多维模型主要包含事实表和维度表。事实表在数据仓库结构中处于多维模型的中央, 包含维度、与维度关联的外键和度量值。维度表是某一个维度属性的集合, 属性的集合构成一个维。维度是用户分析问题时的一个重要工具, 也是重要属性, 通过改变维度来改变观察数据的角度, 更容易获取知识。通常对于简单的数据模型, 一个事实表就可以表示一个主题, 一个事实表对应多个维度表。
采出井生产数据分析的主要维度包括日期、井别、驱动类型、采出方式、油气品种、井型、油藏类型、油气单元、组织机构等(见表2)。
| 表2 采出井维度表的维度层次描述 |
与采出井生产数据分析相关的主要生产指标包括基础数据、生产数据、状态数据、机采数据、措施数据、关井数据等105项关键指标(见表3)。
| 表3 采出井生产事实表 |
采出井生产数据多维分析属于密集型计算, 星型模型的优点是数据集中运算速度快并且布置相对简单, 但存在数据冗余度较高的缺点, 采用MapReduce并行计算正好可以改善数据冗余度问题, 因此本文采用星型模型。该模型中事实表与所有维度表相连, 事实表占据中间位置(见图3)。
 | 图3 采出井分析数据模型 |
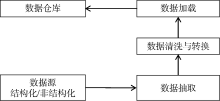
将大庆、吉林、西南等16个油气田公司A2数据库中的油、气、水井生产数据加载到Hive数据仓库中。将事务型数据转变为面向油气生产主题的数据(见图4)。
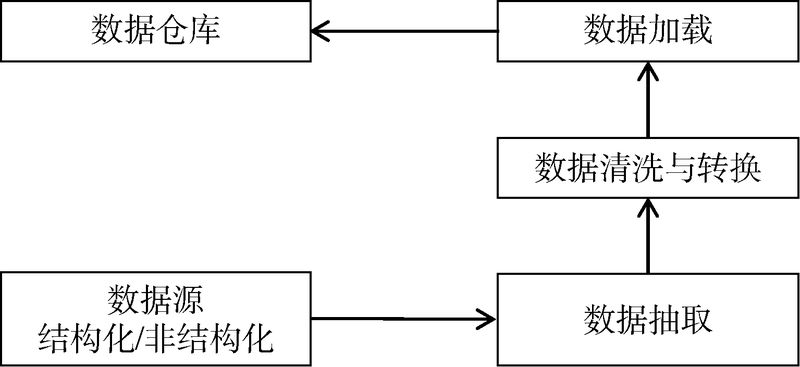 | 图4 数据处理流程 |
16个油气田公司数据库中数据量巨大, 抽取数据时需要设置一个数据缓存区, 将数据一次性地从数据库中读取出来。在数据抽取过程中, 先将数据抽取到临时数据存储区, 然后进行数据的转换和清洗。转换工作是将生产数据中格式不一致、单位不统一的数据进行规整处理; 清洗的工作主要是删除重复信息、纠正存在错误的数据[25]。
本次作业流程中包括了日期、井别、驱动类型、采出方式、油气品种、井型、油藏类型、油气单元、组织机构等维度与油气生产事实表。这里对每个维度都进行相应的定义, 如时间维度, 如果原数据是一个日期字段, 要进行拆分, 最小粒度为天, 将时间拆分为年、季度、月、日。而其他维度按照上述规则, 进行度量统一、空值处理、类型转换等操作。经过作业流程和转换流程的协同工作, 最后形成星型模型。
数据预聚合主要是对Hive数据仓库中的油气生产数据进行数据预聚合处理操作, 以满足OLAP查询请求中较高响应速度的要求。该模块在Kylin引擎的基础上进行二次开发实现, 通过Kylin对外提供的接口来使用其内部功能, 并在原有功能的基础上进行系统功能扩展, 以满足对自动化运行、管理、监控和报警等方面的需求。
多维立方体作为OLAP数据分析的重要对象, 它是逻辑上的一种数据组织形式, 本文采用四元组(D, M, A, F)来对一个多维立方体进行定义。四元组中的不同元素从不同角度对该立方体的特征进行描述, 其定义如下:
\[\left\{ \begin{align} & D=\left\{ {{d}_{\text{1}}}, \ {{d}_{\text{2}}}, \ \cdots , \ {{d}_{n}} \right\} \\ & M=\left\{ {{m}_{\text{1}}}, \ {{m}_{\text{2}}}, \ \cdots \ , \ {{m}_{n}} \right\} \\ & A=\left\{ {{a}_{\text{1}}}, \ {{a}_{\text{2}}}, \ \cdots , \ {{a}_{n}} \right\} \\ & F=D\to A \\ \end{align} \right.\ (1)\]
约束条件:①\(D\bigcap M=\varnothing \), 表示维度集和测度集不会有交集; ②\({{\forall }_{i, j}}\)且\(i\ne j\), \(f\left( {{d}_{i}} \right)\bigcap f\left( {{d}_{j}} \right)=\varnothing \), 表示任意两个维度的属性集不会相交。
采出井生产数据多维立方体(Cube)的数据分析模型可定义为(Di, Mi, Ai, fi), 其中维度集D包括日期、井别、驱动类型、采出方式、油气品种、井型、油藏类型、油气单元、组织机构9个维度; 测度集M包括井口产液量、井口产油量、井口产水量等生产动态数据; 属性集A包括年、季度、月、旬、日、采油井、采气井、一次采油、注水驱、化学驱、稠油热采、自喷、抽油机、电泵、螺杆泵、射流泵、气举等属性; f表示维度的层次。
Kylin的数据来源是Hive数据仓库, 当生产数据导入到Hive后, 同时需要在Kylin中建立一个数据模型, 并且与数据仓库中的数据模型一致。模型中包括了一个事实表和任意多个维度表, 以及事实表和维度表的关联关系。
当模型设置完成后, 开始构建Cube引擎, 读取Hive中的数据, 插入到一个临时的扁平表中。大量的油气生产数据全部存储在Hive中, 为了更好地管理数据, 提高数据的查询效率, Hive采用分区的方式, 将数据按照时间存放。Kylin框架进行Cube计算的时候, 也是根据时间安排进行运算, Cube的分区列和Hive表的分区列相同, 都是时间列。这样, Hive可以跟着分区迅速找到需要进行计算的数据, 而不需要扫描所有的数据。
MapReduce的计算完成后, 数据直接加载到HBase中。数据是以键值对结构存储在HBase中, 在查询的时候可以直接从HBase中读取数据。
可视化是在数据分析中直观展示数据关系的重要方式。本文采用ASP.NET、Echarts3.0、WebGIS等可视化接口技术将分析结果展示给用户, 最终实现油、气、水井生产大数据分析, 满足实时掌握油气生产动态的需求。
本文利用Hadoop分布式存储与并行计算技术、数据仓库建模技术、Kylin多维分析引擎, 基于油、气、水井全样本分析, 实现油区生产运行跟踪、重点油田生产预警、低产井和长停井现状分析、分类油藏开发规律等应用。在集团公司层级, 油气生产模式分析基本单元由原来的油田细化为单井, 生产管理更为细致(见表4)。
| 表4 分析方式及效果对比表 |
与传统手工分析方式相比:①免去了人工数据准备的工作步骤; ②将常用分析方法形成模板, 实现了统一的多维分析图表, 大幅提升工作效率。以低产井生产分析为例, 应用分析时间由原来的1 d下降到现在的5 s。分析人员只需登录一套系统, 即可实现低产井生产数据多维分析工作, 快速掌握多维度的低产井生产状况。分析结果可以按照集团公司、油田公司、油气田、区块、单井逐级向下追溯, 分析结果更加全面和准确, 可满足实时掌握油气生产动态的需求。
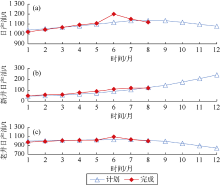
实时跟踪油区的总体生产运行情况, 预判生产趋势并提前发现生产异常(见图5)。分析日产油、新井日产油、措施日增油、月平均含水、日注水、综合递减、自然递减等指标, 预判生产趋势, 及时发现生产异常, 并逐级向油田、区块、生产井进行追溯, 快速、精准定位目标区块, 分析偏离生产计划的原因, 提出开发调整对策。
 | 图5 油区生产运行跟踪分析图 |
建立定量化预警机制, 实现一个人即可监控全部油田的生产动态。主要对日产油、含水上升速度、开井率等主要开发指标进行月度对比分析(见表5)。同时建立定量化油田开发动态预警监控机制, 通过收集油田生产动态信息, 跟踪指标变动趋势, 评价油田开发风险动态, 向决策层发出预警信号, 提前采取预控对策。系统监控对象已覆盖集团公司全部油田, 实现全方位、多角度开发监控, 全程跟踪各油田生产形势, 对生产指标异常的油田或区块及时监控预警, 提出整改建议, 及时指导生产。
| 表5 油田生产动态预警表 |
分析低产井、长停井现状和治理效果, 共享治理经验, 利用大数据技术筛选出潜力井。目前大部分油田开发进入中后期, 低产井、长停井数呈逐年上升的趋势。采用该系统可实现低产井生产现状、历史变化趋势及长停井关停原因等分析(见图6— 图8), 并可利用大数据技术筛选出治理效果显著的潜力井, 为集团公司低产和长停井治理、盘活油井资产利用率等提供借鉴。
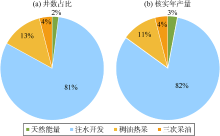
 | 图6 不同开发方式低产井多维分析图 |
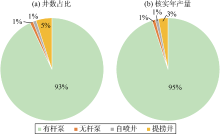
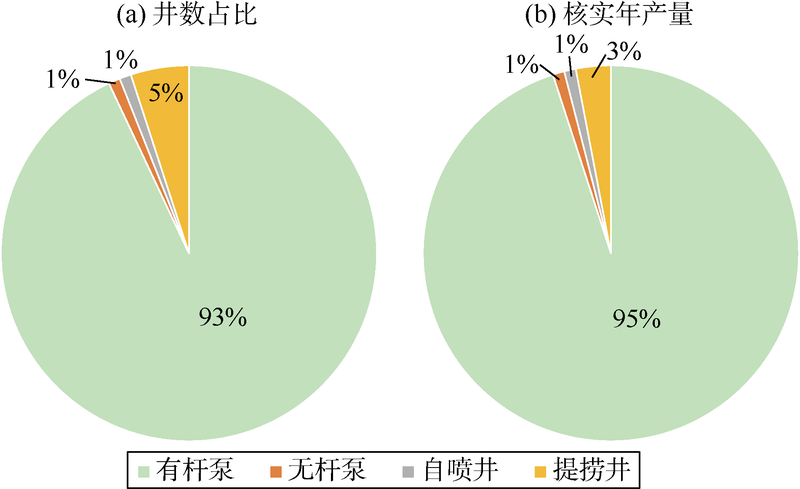 | 图7 不同举升方式低产井多维分析图 |
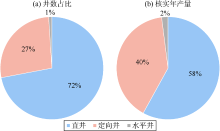
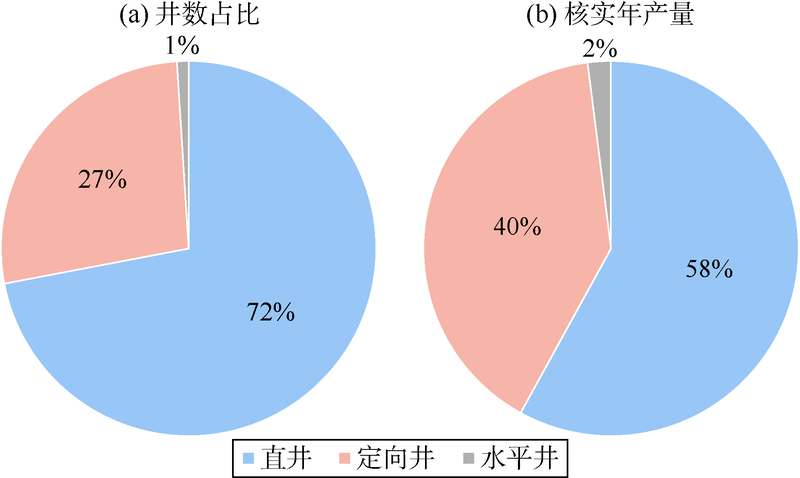 | 图8 不同井型低产井多维分析图 |
在集团公司内实现不同油区、相同类型油藏开发指标类比, 对标高效开发方式, 充分挖掘油藏资源潜力。实时跟踪中高渗透砂岩、低渗透砂岩、砾岩、稠油、特殊岩性油藏等的油、气、水井生产情况, 从已开发油藏中筛选出“ 双高油藏(综合含水大于等于80%, 可采储量采出程度大于等于60%的开发单元)” 、“ 双低油藏(采油速度小于等于0.5%、地质储量采出程度小于等于10%的开发单元)” 和“ 双负油藏(双高和双低油藏中利润与现金流均为负值的开发单元)” 。针对每类油藏, 统计分析其开发方式、分布状况、生产效果等, 总结经验, 支撑分类油藏治理工作(见表6)。
| 表6 分类油藏开发规律分析统计表 |
大数据分析系统实现了36× 104余口油、气、水井生产数据的集中管理, 为在集团公司层级实施油、气、水井全样本分析提供了技术支撑, 同时也为数据挖掘奠定了基础, 将来通过整合油气田开发、数据挖掘和人工智能等技术, 定可深入透视分析油气生产数据背后潜在的有用信息, 提升数据资产的价值, 更好地为油气生产与科研服务。
采用Hadoop分布式存储与并行计算技术、数据仓库建模技术, 构建Kylin多维分析引擎数据管理平台, 实现了分散存储油气生产动态大数据的优化管理与快速查询, 可集中管理36× 104余口油、气、水井的生产数据。
建立了油、气、水井生产多维分析主题模型, 对数据进行预处理, 可实现系统的秒级响应; 油区生产运行跟踪、重点油田生产预警、低产井和长停井现状、分类油藏开发规律等分析应用等可取代传统人工收集数据、手工分析的方式, 工作效率大幅提升; 油气生产模式分析基本单元由原来的油田细化为单井, 生产管理更为细致; 分析结果可以按照集团公司、油田分公司、油气田、区块、单井逐级追溯, 更加全面和准确, 满足实时掌握油气生产动态的需求。
符号注释:
A— — 属性集; ai— — 属性名; D— — 维度集; di— — 维度名; F— — 维度集到属性集的一对多映射; f— — 维度层次; i, j— — 维度序号; M— — 测度集; mi— — 测度名; n— — 子任务数量。
(编辑 唐俊伟)
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|