

0 引言
但是,关于微观复杂结构中多相流的深度学习建模研究相对较少。Rabbani等[14]训练了一个CNN,用于预测仿真三维多孔介质中的两相流相对渗透率和莱弗里特(Leverett)J函数。在流场方面,Feng等[15]设计了一个CNN模型,用于估计侵入相突破时的二维压力场和饱和度场。Wang等[16]提出了一种条件生成对抗网络(GAN),成功模拟了低毛管数条件下排驱过程中的流体分布。Yu等[17]采用一个带有密集跳跃连接的注意力U-Net网络,来预测水驱气0.8 ms时的饱和度和压力场。多相流神经网络模拟最主要的挑战在于将这些神经网络模型应用于复杂孔隙结构。目前多数学者通常仅考虑简单的多孔介质,这严格限制了模型在不同岩石类型上的适用范围,导致模型的实用性有限。此外,除图像本身,多数研究未将流体、固体、流体-流体或流体-固体属性以及驱替参数作为输入,导致这些模型不能反映压敏及速敏特征。
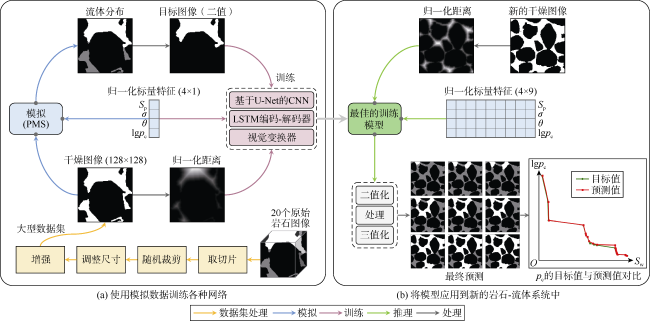
本文研究孔隙尺度下真实岩石-流体系统中毛管压力主导的两相驱替过程。首先将岩心饱和润湿相流体,采用非润湿相流体逐级加压驱替岩心,在每个平衡压力下,预测润湿相饱和度和流体分布图像。具体来说,本文训练一个DNN,基于孔隙-固体图像预测每个毛管压力(pc)下的流体分布。模拟时将流体像素分为被驱替和未被驱替两类,考虑局部流体-流体和岩石-流体的相互作用,非润湿相在空间和时间维度上与入口保持连通。
在本文模型中,毛管压力(pc)、像素大小(Sp)、界面张力(σ)和接触角(θ)作为标量特征与岩石图像一起作为模型的输入参数,而其他类似研究仅将岩石图像作为输入参数。此外,本文研究与其他类似研究相比还存在以下几点改进或拓展:①构建一个多样化的、由数值模拟器模拟结果构成的大型数据库,该数据库在其他研究中尚未见报道;②利用本文方法可避免复杂的特征提取过程,生成通用的端到端深度学习模型;③本文探索3种截然不同的DNN网络,并对比它们的优势和不足;④本文引入一种简单有效的策略,允许在任意出入口设置下进行与图像尺寸无关的预测,使得模型能够在多尺度、多边界条件下应用。
1 数据集生成
沿着X、Y、Z轴方向对上述原始图像进行切片。在这些切片上随机定位中心,裁剪出多个矩形子图像。子图像的高度和宽度(单位为像素)从平均值为128像素、标准差为24像素的正态分布中随机选取。然后,将这些矩形重新调整为1282像素,从而得到子样本。图1 展示了岩石样品的孔隙度统计直方图及从各类型岩石中采样的10个子样本示例。其中,砂岩和碳酸盐岩表现出了最大的内部多样性。
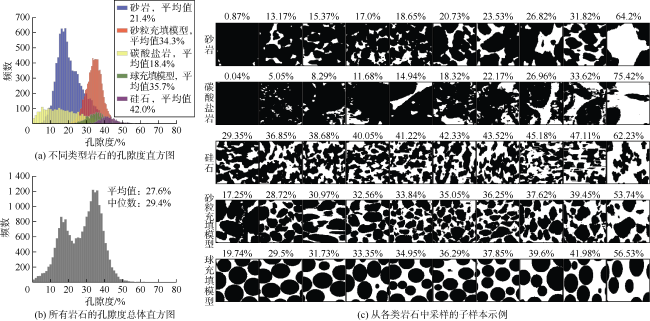
为了增加数据量,本文对数据集进行7种仿射变换:旋转90°、180°和270°,水平翻转和垂直翻转,以及水平翻转和垂直翻转后再旋转90°,最终子样本数量为177 360个。为了形成与训练数据集不同的测试数据集,在上述20个原始岩石图像中,从Z轴方向等距地选取5个切片,并提取位于中间的边长为128像素的子样本,排除其中孔隙未连接到入口的样本后,获得了97个测试图像。
假设一个二元多孔介质(见图2a )左侧(入口)连接到非润湿相池,右侧(出口)连接到润湿相池,除出入口外其他边界皆为密封(即流体不可渗透)。计算每个孔隙像素点到最近固体像素点的欧几里得距离,得到距离图(见图2b )。然后按以下步骤进行计算。

①对每个预设毛管压力(pc),计算两个半径:r=2σ/pc和r°=rcosθ。
②通过移除距离值小于等于r°的所有孔隙点,将孔隙空间“腐蚀”为较小的子空间,得到被侵蚀的孔隙区域(见图2c 中紫色区域)。图2 中的蓝色区域与入口不连通,将不会被驱替。
③去除与入口非润湿相池不相连的腐蚀孔隙区域,得到剩余的与入口相连的腐蚀孔隙区域(见图2d 中紫色区域)。
④计算一个新的距离图,以获得每个孔隙点到剩余区域(图2d 中紫色区域)的最短距离。计算新的距离图时,剩余区域的点赋值为零。固体点被赋予无限大,以防止非润湿相侵入。
⑤使用新的距离图,将距离值小于等于r的所有孔隙点与剩余区域合并成更大的空间,形成新的膨胀区域(见2e中红色区域)。膨胀区域被认为已被非润湿相侵占。图2f 中绿色区域可认定为被非润湿相包围的润湿相,在更高的压力下它们可能将全部被侵占。
⑥对下一个pc(对应更小孔径)重复上述步骤,直到满足预定义的停止标准。
假定存在薄膜/角隙流动,按压力增加的顺序逐步排驱(即非润湿相驱替润湿相),直到未隔离孔隙被完全驱替。对每张图像进行3次PMS模拟,每次从以下均匀分布中随机选择属性参数:Sp:[1 μm, 50 μm],θ:[0°, 60°],σ:[0.015 N/m,0.065 N/m]。记录每次模拟中对应不同lgpc的流体分布。
PMS模拟后,将相应的图像转换为欧几里得距离图,并按最大距离进行归一化处理。同时对pc进行对数转换,并对所有标量特征进行最小-最大归一化。最后,将流体分布二值化,其中1表示非润湿相,0表示润湿相和固体。因此,预测结果将是非润湿相侵入的概率图,最终通过Otsu阈值分割算法来确定每个孔隙点归属于非润湿相还是润湿相。
2 模型建立和分析
本文通过改造、训练、评估卷积神经网络、递归神经网络(RNN)和视觉转换器(ViT),优选出用于预测流体分布的模型。图3a 概述了使用PMS模拟结果进行训练的过程。模型将距离图和标量特征作为输入,流体分布作为输出。所有训练在Nvidia RTX 3080 GPU(16 GB)上以32位精度模式进行,使用二元交叉熵(BCE)损失函数和Adam优化器[30]。图3b 展示了如何使用训练好的模型在一系列压力下预测新的岩石-流体系统中排驱过程流体分布。
2.1 基于U-Net网络的CNN
首先训练1个CNN直接根据输入数据预测流体分布。由于大多数真实岩心二维样品从入口到出口并不连通,此处采用球充填模型的流体分布图像数据。在保证饱和度分布均匀的前提下,从原始的732 772个流体分布图像中选择261 618个实例,其中90%用于训练网络,10%用于模型测试。
2.1.1 架构和训练
2.1.2 测试
使用222个训练中未使用的球充填模型实例来评估Y-Net。结果如下:F1分数为0.938 0,交并比为0.880 6,均方误差为0.017 8,非润湿相饱和度相关系数为0.956 9。这些结果表明尽管模型表现出一定程度的过拟合,但模型具有较高的像素级精度。总体而言,该网络可模拟正确的pc范围内从孔隙中排出润湿相的过程,这通过较高的非润湿相饱和度相关系数得以证明。此外,Y-Net运算速度非常快,只需0.065 s就能生成1个流体分布。
然而,Y-Net偶尔会出现3种类型的错误:①侵入相断开;②出现锯齿状或像素化的流体界面;③驱替终止于孔隙内而不是在喉道中。图4 中展示了Y-Net在球充填模型和其他岩石样品上的最严重的错误示例。必须注意,这些错误并不代表平均性能,大多数错误都与模型未能建立一个完整的非润湿相连通体有关。如图4b 所示,最终得到了pi+1下正确的流体分布,但如pi下流体分布所示,驱替并未沿连续驱替路径推进。

2.2 卷积LSTM编码-解码器
改造模型使其参考前几行的流体分布,可以激励模型保持非润湿相的连通性。为此,沿流体入侵方向(即从入口至出口,例如Y轴方向从上至下)对图像进行排序,创建一个由连续、重叠窗口而非单独图像组成的新数据集。窗口是一个序列数据单元,其大小(厚度)是一个关键超参数。序列模型通过逐一分析窗口内的行来累积记忆。训练好的模型能够通过重复使用其自身先前的预测(前一窗口内的流体分布)以及当前窗口新的输入(距离图和标量特征)来进行自回归预测,以便推断当前窗口的流体分布,从而获取平滑有效的驱替过程。
与Y-Net类似,在确保均匀的饱和度分布的前提下,从球充填模型中选择合适的子样本。经过大量实验,选择了32的窗口大小,以达到性能和计算成本的最佳平衡。以步长1进行窗口滑动,得到140×104个窗口,选择一半的窗口进行训练,获得700 044个实例,其中10%被分配给测试集。
2.2.1 架构和训练
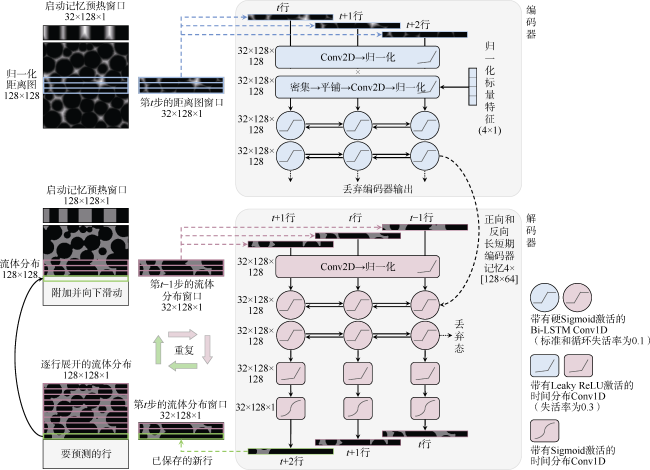
该模型具有3个输入和1个输出的架构,形成一个“Ψ”形,将其命名为Ψ-Net。以批量大小32、初始学习率0.001进行10周期的训练,每个周期平均需要764 min。
2.2.2 测试
使用222个训练中未使用的球填充模型数据评估Ψ-Net,结果显示:F1分数为0.920 4,交并比为0.853 1,均方误差为0.027 3,非润湿相饱和度相关系数为0.934 4。图6 绘制了3个训练中未使用的测试样品的不同阶段目标(PMS)流体分布之和以及预测(Ψ-Net)流体分布之和。暖色表示驱替早期阶段,冷色表示较晚阶段。总体而言,结果是令人满意的,尽管Y-Net的像素级图像匹配稍高,但Ψ-Net在满足物理连通性要求方面表现更好。
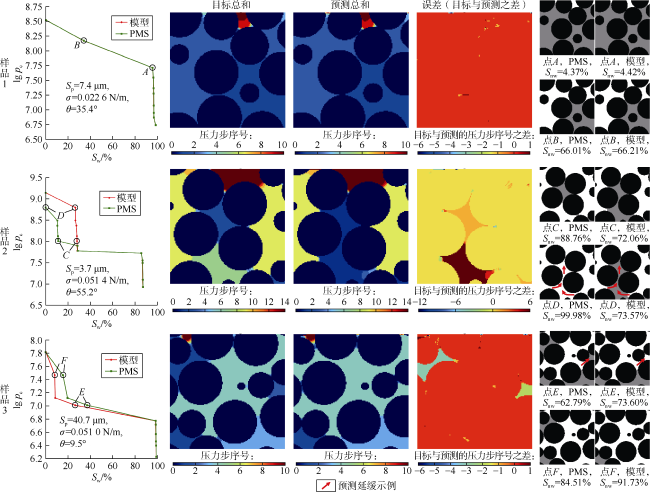
众所周知,RNN模型预测误差会逐渐累积。也就是说,长时间自回归预测会导致性能显著下降。图7 绘制了图6 中3个样品各行的3个指标平均值。依图可见没有证据显示误差(纵轴)会随着行数(横轴)的增大而呈现累积现象。
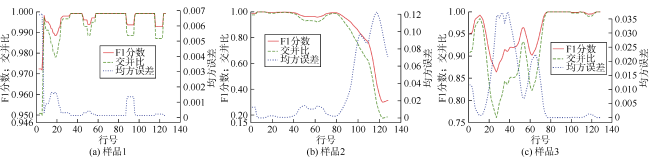
此外,Ψ-Net似乎容易受到方向偏差的影响,驱替流体沿数据排序相同方向(向下)驱替时,模型表现最佳。图6 中的样品2展示了1个实例,如红色箭头所示,方向偏差使得预测延缓了多步。尽管如此,Ψ-Net最终能够在更高压力下重现所有非向下方向的驱替。但在少数情况下,Ψ-Net甚至比PMS模拟更早地以非向下方向侵入特定孔隙(见图6 中样品3)。除了方向偏差的影响外,Ψ-Net还存在序列模型训练速度缓慢、自回归推断耗时长等局限,Ψ-Net生成一个流体分布平均需要2.898 s。
2.3 更高维数据的视觉转换器
假设孔隙没有空间顺序关系,所有位置的孔隙对非润湿相可及,那么排驱过程将仅基于孔隙尺寸而展开。这等同于视每个孔隙都是独立的,从而暂时不考虑要保证非润湿相连通的要求。为实现这一目标,本文修改模拟器,跳过前文PMS模拟中的第③步(即去除与入口不连通的侵蚀孔隙区域)。其结果相当于在Z轴方向沿更高维度对二维岩石进行三维模拟。一旦模型生成流体分布预测,可以通过排除与入口不连通的被驱替区域来间接施加连通性要求。
这种方法在模拟过程中无须考虑端到端流体的连通性,所以可以在所有岩石图像上运行更高维度的模拟。在确保均匀的饱和度分布的前提下选择样本,最终的数据集包含了9 551 504个实例,其中3%用于测试。
2.3.1 架构和训练
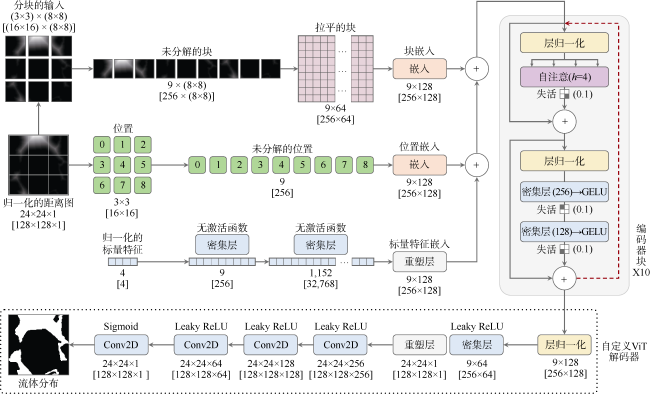
为了增加切块顺序的信息量,生成一个区间$[0,N)$内的整数向量,并通过一个可训练的嵌入层(256×128)将其线性投影到一个128维空间。为了整合标量特征,采用一对密集层和一个重塑层将其调整为相同尺寸(256×128),然后把所有切块、位置、标量嵌入加在一起,形成一个转换编码器的组合表示。
本文提出的ViT由10个堆叠的块组成,每个块包含1个多头自注意力模块和1个前馈模块。在基础的自注意力中,Z被转换为3个矩阵:查询(Q)、键(K)和值(V)。采用这些矩阵根据(1)式通过缩放点积计算注意力值。这种方法并行运行h个自注意力,称为“头”。所得结果被串联起来并经过线性变换以生成最终输出。本文多头自注意力模块有4个“头”。前馈模块有两个使用GELU激活函数的密集层[38]。
$\text{Attention}\left( Q,K,V \right)=\text{Softmax}\left( \frac{Q{{K}^{\text{T}}}}{\sqrt{d}} \right)V$
编码器的输出被传递给一个定制的卷积解码器,用于生成流体分布。通过将CNN作为解码器融入模型,本文在架构中加入了一些空间归纳偏差(如局部性和平移等变性),使模型更好地识别全局和局部模式。
使用更高维数据以批量大小64、初始学习率0.000 5训练ViT(HD-ViT)。训练在8个周期后结束,每个周期耗时略超过13.5 h。
2.3.2 测试
本文通过创建一个独立的数据集来测试HD-ViT,该数据集由各岩样的6 323个高维流体分布图组成。图9 比较了各类岩石的目标流体分布和预测流体分布。结果显示F1分数、交并比、均方误差和非润湿相饱和度相关系数分别为0.962 5,0.927 0,0.003 9和0.966 5,表现非常出色,并且对所有岩石类型效果一致。HD-ViT生成一个流体分布仅需0.037 s,比Ψ-Net快了两个数量级,大约是Y-Net速度的两倍,说明模型效率非常高。更重要的是,HD-ViT确保了在整个侵入过程中非润湿相保持连通性。此外,通过将样本的不同侧面作为入口(多边界特征),对同一图像可以产生几个流体分布预测,这在数据量上为模型的鲁棒性提供了保证。
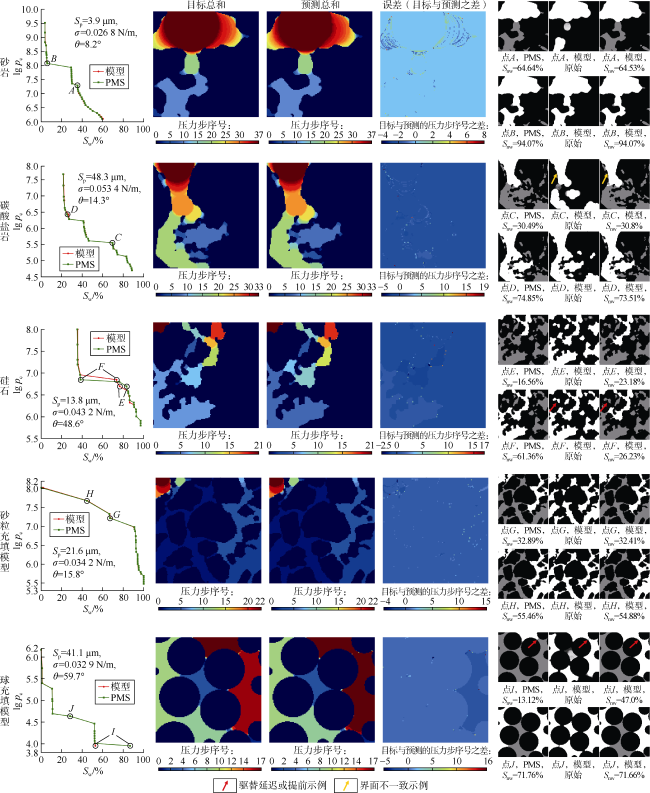
预测结果的不确定性主要来自于驱替边缘的孔喉。如图9 中硅石(点F)和球充填模型(点I)样本中红色箭头指示处驱替分别被延迟和提前。在这两种情况下,HD-ViT和PMS的结果在下一个pc时对齐。这表明,尽管HD-ViT在预测流体到达出口的路径方面表现近乎完美,但正确的分布可能会在稍低或稍高的pc下呈现。有时在流体界面处可观察到不确定性,尤其在砂岩和碳酸盐岩样品的误差图中较为显著。这说明HD-ViT预测结果与PMS在物理意义上是一致的。然而,由于使用简单二值化法分割流体分布概率图,偶尔可能会形成不一致的界面,如碳酸盐岩样品一个样本中所示(见图9 中黄色箭头指示处)。
3 模型验证和三维扩展
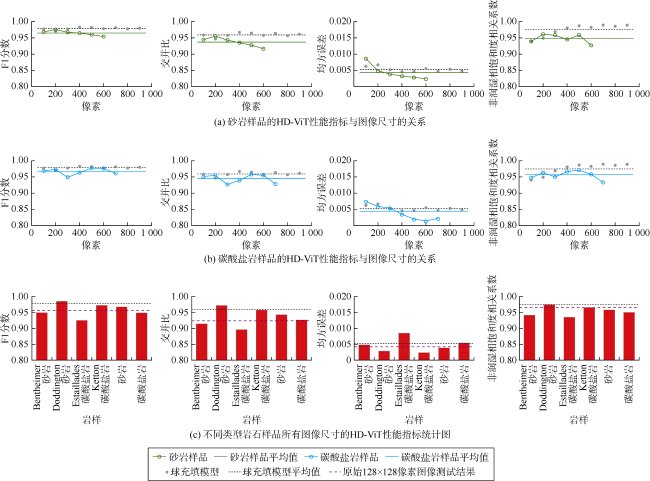
3.1 模型性能与岩石类型及图像尺寸的关系
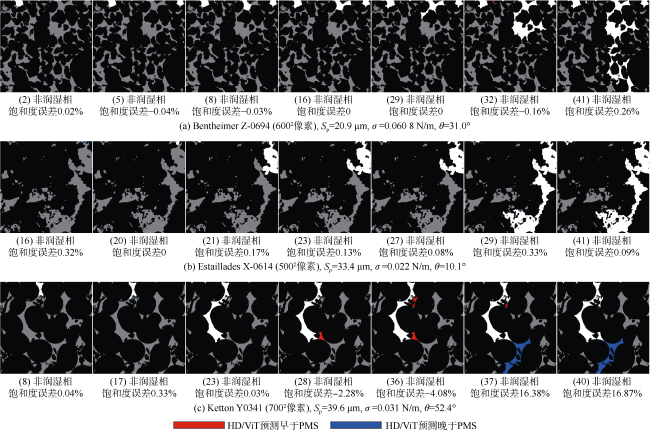
为创建从入口到出口非润湿相连通的新样品,从X、Y、Z轴方向的所有切片中随机定位而提取正方形二维子图像。然后,去除孔隙未从一端连接到另一端的图像。在增强(180°旋转和水平/垂直翻转)之后,对每张图像进行3次PMS模拟。最后,随机选择至多100个模拟结果进行测试。为了对更大的图像进行预测,距离映射是零填充的,并以64的步长分解成大小为1282像素的块。然后将输出裁剪掉一半的重叠部分,并拼接在一起以重建完整的新图像。图10 展示了大图像上的3个预测示例。尽管HD-ViT在某些毛管压力下预测略有提前或滞后,但孔隙排驱顺序却是精确的(见图10 Ketton岩样)。
3.2 模型运行时间与PMS运行时间对比
将单相分布下HD-ViT的平均运行时间与PMS的平均运行时间进行比较。图12a 显示了运行时间与分块步幅(patching stride)和图像尺寸的关系。可见,随着步幅变大,网络运行显著加快。为了更直观地比较,绘制了图12b 所示的运行时间与处理像素数的关系,可以看出,HD-ViT的运行时间与处理像素数间符合线性关系。HD-ViT起初比PMS速度慢,但在某个临界尺寸上速度超过PMS。该临界尺寸是图12c 中趋势线的交点,为509.02。对于步幅128、112和96,这些点对应的临界尺寸分别为509.02,692.92和1 051.02;对于步幅64,则不存在交点,没有相应的临界尺寸。
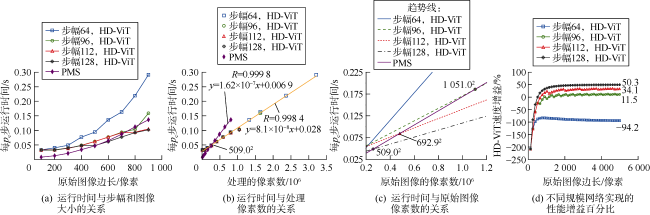
由于运行时间遵循线性趋势,在足够大的图像中, HD-ViT运行时间与PMS运行时间相比缩短或延长的百分比应会收敛到一个恒定值。此百分比表示HD-ViT相对于PMS所实现的最终速度增益。如图12d 所示,与PMS相比,64的步幅将使运行时间大致翻一番,使运行速度降低94.2%,而96,112和128的步幅则会使运行速度分别提高11.5%,34.1%和50.3%。
3.3 实验验证
如图13a 所示,McClure等[42]向饱和癸烷(润湿相)的二维微流控装置注入氮气(非润湿相),捕捉微流控装置中孔隙空间内的流体分布;引入了一种平均方法来近似表达微尺度毛管压力,所使用的界面曲率和准确压力场采用基于实验流体分布图像初始化的LBM模拟(简称LBM-E)得到;还开展用随机流体分布初始化的LBM模拟(简称LBM-R),以建立全范围的流体饱和度分布。
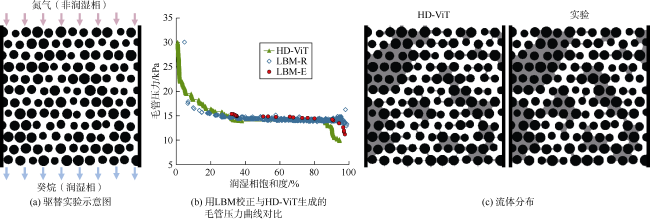
本文使用与McClure等[42]文献中相同的界面张力(24.7 mN/m)、接触角(4.1°)和入渗压力范围,运用HD-ViT来预测两相流体分布。图13b 显示了生成的毛管压力曲线,证实HD-ViT可以再现压力-饱和度关系。特别是能准确识别大部分发生癸烷去饱和的区域(饱和度20%~90%),该区域LBM-E与HD-ViT结果之间的较小差异可能是由于两种方法之间固有差异所致。LBM-R与HD-ViT在高润湿相饱和度下的差异可能是LBM-R的随机性造成的(LBM-R和LBM-E本身就不完全匹配)。
为比较流体分布,通过追踪润湿相与出口的连通性来校正HD-ViT结果,以考虑润湿相束缚饱和度,即如果任何充满润湿相的区域在某一压力下与润湿相池断开,在后续步骤中不再允许非润湿相入侵该区域。如图13c 所示,最终预测的排驱模式与物理实验的图像基本吻合。图13 所示是经过1 000多个压力步的HD-ViT预测结果,仅需大约1 min。
3.4 三维扩展探讨
值得进一步研究的问题是HD-ViT是否可以通过较少的改动适用于三维领域,即输入和输出的图像和流体分布都是三维的。本文通过将20个原始岩石图像分解为尺寸为643像素的重叠立方体来创建一个三维数据集。在均匀饱和度分布下选择367 842个实例。为了生成测试数据,从每个新的三维岩石图像中取一个尺寸为2563像素的中心立方体,通过模拟生成总共696个流体分布用于测试。
要将HD-ViT应用于 3D场景,需进行两项关键改动:①输入($Z\in \mathbb{R}{}^{N{{D}_{\text{e}}}}$)图像或流体分布应为三维体;②解码器改造为三维CNN。后者较为简单,前者可以通过使用视频视觉转换器(ViViT)[43]中用于将视频标记化的tubelet嵌入来实现。在改进的HD-ViViT中,将每个三维图像划分为512(N)个尺寸为83像素的非重叠三维子体积。然后,这些子体积被展开以嵌入维度(De)256进行线性投影。范围在$[0,\ 512)$内的整数向量和标量特征也以相同尺寸(512×256)嵌入。该模型以初始学习率0.000 5训练6个周期,每个周期9.5 h。
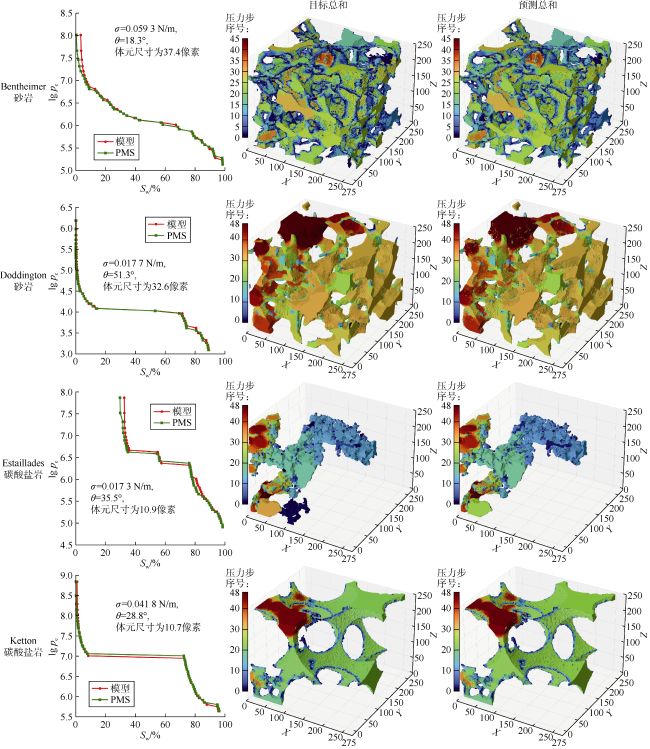
对于尺寸为2563的样本,测试的F1分数、交并比、均方误差和非润湿相饱和度相关系数分别为0.968 4,0.944 0,0.003 6和0.989 5。图14 比较了每块测试岩石的1次模拟的PMS目标和HD-ViViT预测结果。HD-ViViT成功再现了在不同像素大小(Sp)、界面张力(σ)和接触角(θ)条件下各类岩石中驱替流体的空间分布。结果显示HD-ViViT在捕捉孔隙尺度三维流动方面存在较大的潜力。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4 结论
本文考虑了压力分布范围和岩石-流体特性,引入了一种准确的视觉转换器(HD-ViT),用于从孔隙-固体图像中预测毛管压力主导的两相流驱替过程中的流体分布。该模型在孔隙形态模拟器(PMS)生成的大型多样化数据集上进行训练,通过在训练中未使用的砂岩和碳酸盐岩大图像上验证,并与微流控驱替测试的实验结果比较,充分验证了模型的有效性和精确性,展示了HD-ViT的速度优势。
在一定的容错精度下,训练好的模型可以用来替代耗时的数值模拟或冗长的流控实验,还可以用于生成更精细的压力步骤上更完备的模拟结果。此外,该模型可以针对高质量、计算密集或实例有限的特定领域数据集进行微调。预测结果也可以作为初始条件来加速数值模拟过程。由于其速度优势,模型可以作为快速预测器集成到其他工作流程中,例如不确定性/敏感性分析和逆问题(如通过相态分布反向估计流体-固体接触角)。更为重要的是,基于转换器模型的可扩展性,加上高维方法的多尺度处理能力,使得大图像(如1283~1 0243像素)的分布式计算也将成为可能。因此,本文方法可以成为解决图像尺寸、数据集大小和计算能力受限问题的有力手段。下一步将继续研究该方法在三维模拟中的应用,同时增加更多输入属性,并实现对渗吸和动态驱替过程的建模。
符号注释:
De——嵌入维度;d——键向量的维度;h——自注意力的个数;N——序列长度;pc——毛管压力,Pa;pi,pi+1——第i和i+1时间步时入渗压力差,Pa;Q,K,V——表示查询、键和值的矩阵;$\mathbb{R}$——实数空间;Sp——像素大小,μm;Sw——润湿相饱和度,%;Snw——非润湿相饱和度,%;t——行号;X,Y,Z——直角坐标系;Z——输入张量;σ——界面张力,N/m;θ——接触角,(°)。