

0 引言
深度学习是测井曲线重构的主流方法。然而,研究表明[6-12],深度学习方法虽然具有较好的测井曲线重构精度和模型局部泛化能力,但高度依赖于充分的邻井数据或目标地层的地质特征。例如,基于数据驱动的模型[6-10]对目标井邻井数据存在明显依赖性;基于物理约束的模型[11-12]需设置对应储层特性的物理约束条件。因此,在跨油藏应用中(即模型在未训练过的油藏中的应用),传统深度学习小型模型(后文简称小型模型,指参数量小于1×108、采用全监督训练的常规架构)难以同时保持稳定泛化能力和高精度重构效果。此外,模型与测井数据集日益增长的规模之间的匹配也是关键挑战。尺度效应(Scaling Law)[13]揭示,模型参数量、训练数据量存在约束关系,需保持同步增长。而小型模型存在神经网络表达能力的局限性,随着测井数据集规模增加,小型模型的应用容易出现瓶颈[13-15]。实际应用中,小型模型也需针对不同油藏类型建立独立模型,显著增加了建模成本与工程复杂性。相对而言,人工智能大模型通常具有显著的大规模数据集学习能力与泛化潜力[16]。这类模型通过学习大规模数据集中的通用知识[17-19],能有效捕捉复杂序列的依赖关系与周期性特征,并建立数据间的数学与物理规律映射。
本文将大语言模型引入测井曲线重构任务,提出基于适配器(Adapter)技术的盖亚模型。该模型以预训练大语言模型解码器为骨干网络,充分利用其序列特征提取能力,同时通过适配器微调实现领域任务适配。基于大规模测井数据集对盖亚模型进行训练,使其在保留大模型通用知识优势的基础上,显著提升曲线重构精度与跨油藏泛化性能。
1 原理与方法
尽管大语言模型在通用任务中表现卓越,但其在垂直领域的应用仍存在显著挑战。以测井曲线重构任务为例,不仅需要模拟物理参数的连续变化特征,还需捕捉垂向空间维度的地质关联性,因此要求模型具备连续型数值序列的回归预测能力和物理数值映射能力。然而,大语言模型最初针对自然语言任务设计,其预测目标以离散数据为主。与自然语言生成等任务不同,测井数据具有以下特点:①物理规律复杂。测井曲线包含多种物理量(如声波、密度、电阻率等),不同传感器之间存在非线性物理规律关联。②数据噪声与缺失。由于地下环境复杂,测井数据常含有大量噪声或缺失值。③非平稳性。由于油藏地层的非均质性,不同深度段的数据分布差异显著。④空间依赖关系。测井任务需模拟地层空间维度的依赖关系(地层均质性、地层沉积韵律性等)。现有大语言模型未针对测井曲线重构任务对数值稳定性和空间连续性进行专门的结构优化,无法直接适配此类任务。
针对上述问题,本文提出盖亚模型,通过适配器技术实现大语言模型对测井数据的领域适配。图1为盖亚模型重构测井曲线流程示意图:首先,对原始地层测井数据进行标准化预处理与深度维度序列化操作,构建具有地质连续性的输入特征数据;然后,将输入特征数据输入至盖亚模型中,完成对该序列数据的高维特征提取与物理关联映射;最后,盖亚模型会将提取的特征结果进行再映射,端到端重构出输入特征同深度段的目标曲线。

图2是盖亚模型的具体结构,主要包括输入结构、解码器主体、输出结构、适配器结构。其中,输入和输出结构的设计旨在适应测井曲线重构的特定要求,解码器主体负责提取测井曲线的序列特征和空间特征,适配器结构负责领域任务的迁移学习。各主要结构的特点如下。
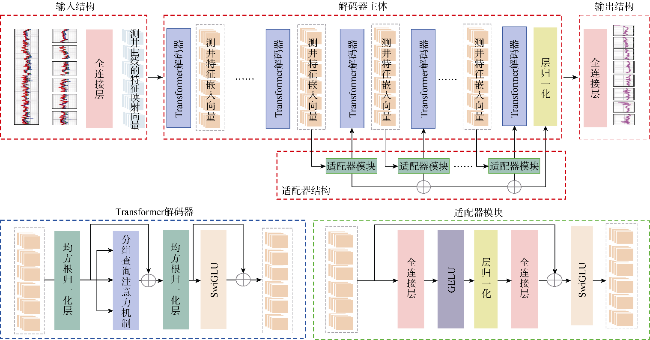
①输入结构。针对测井曲线连续型数值数据的空间特性和地层沉积韵律特征,移除了传统文本嵌入层,采用全连接层组成的输入结构进行特征映射。输入结构将声波时差、电阻率等多维测井参数映射至高维特征空间形成测井曲线特征映射向量。其中,该方法既保留了数据中的深度依赖关系,又实现了输入维度与解码器主体的精准对齐。
②解码器主体。解码器主体接受并处理测井曲线特征映射向量,通过内部的Transformer解码器将测井曲线特征映射向量转化为测井特征嵌入向量,从而利用大语言模型的解码能力实现高维特征提取与物理关联映射。解码器主体为盖亚模型的核心部分,沿用Llama 3.1预训练的解码器架构,依托预训练的分组查询注意力机制(Grouped Query Attention)、均方根归一化(Root Mean Square Normalization,RMS Norm)层和SwiGLU(Switched Gated Linear Unit)激活函数。其中,预训练的分组查询注意力机制和均方根归一化层有效提取测井数据的非线性序列特征与空间特征,强化了对复杂油藏物理规律的建模能力。SwiGLU激活函数凭借其平滑的非线性响应特性,在保留关键物理特征的同时,能有效削弱异常数据点的过度激活风险。解码器主体为Llama 3.1-8B模型(8B即参数量为80×108)的32个预训练解码器模块。解码器主体作为非线性信息整合层与多尺度特征提取层,包含了70×108(7B)的参数量,是Llama模型最主要的神经网络结构。解码器主体在训练中是冻结状态,其余结构均为可训练状态。
③适配器结构。适配器结构接受解码器主体的部分测井特征嵌入向量,并且对其进行适配处理后输回解码器主体中后续的Transformer解码器中,从而完成模型微调的目的。适配器技术可以极大降低模型的训练成本,仅训练1%~5%的本体参数,就能将预训练的大模型迁移适配至某个垂直领域[22]。因此,参考前人研究[23],在靠近输出端的6个解码器前引入适配器模块,仅微调1.4%的本体参数即可实现大模型向测井领域的快速迁移。相较于常规适配器设计,盖亚模型在适配器模块使用了层归一化(Layer Norm)、GELU(Gaussian Error Linear Unit)激活函数和SwiGLU激活函数。其中,Layer Norm通过动态调节每层输出的均值和方差,显著抑制了测井数据噪声引发的梯度异常波动;GELU激活函数通过近似高斯分布的平滑过渡,能抑制异常点的影响,提升重构鲁棒性;SwiGLU激活函数能在最后进一步削弱异常数据点的过度激活风险。此外,在适配器模块后引入了多段残差连接,通过传递适配器模块的特征信息,既缓解了梯度消失问题,又实现了误差反馈的定向调节,大幅提升了训练效率。
④输出结构。采用全连接层作为输出层,确保重构曲线在数值格式上与真实测井数据保持对齐。输出结构将适配器和Transformer解码器处理过的测井特征嵌入向量通过层归一化调整数值分布后,利用全连接层将其映射回测井曲线序列。这种端到端的架构改造,使模型在保持大语言模型特征提取优势的同时,形成了适配地球物理领域的专用数据处理能力。
2 实验
2.1 数据预处理
本文使用的数据集涵盖了250口井的测井曲线数据,包括来自加拿大Fox Creek地区的测井数据集(50口)、中国中西部某油田测井数据集(100口)和中国东北部某油田测井数据集(100口)。为了保证数据的广泛适用性并减小数据缺失的影响,本文仅选择基础且常见的测井曲线作为模型输入。其中,输入特征包括中子孔隙度曲线(%)、声波时差曲线(μs/m)、原状地层电阻率曲线(Ω·m)、自然伽马曲线(API),预测目标为密度曲线(kg/m3)。为了减少异常数据对模型的影响,本文采用四分位法(Interquartile Range,IQR)对训练集中的测井数据进行清洗。测井数据的合理范围为[Q1-1.5 IQR, Q3+1.5 IQR],超出此范围的数据点被视为异常点,并在数据清洗过程中被剔除。其中,Q1、Q3分别为第1四分位数和第3四分位数,IQR为四分位距,IQR=Q3-Q1。经过数据清洗后的测井数据统计指标如表1所示。此外,采用最小-最大归一化方法对数据进行了归一化处理,以确保模型在训练过程中的稳定性和预测性能。
表1 数据清洗后的测井数据统计表 |
| 指标 | 密度/ (kg·m-3) | 中子 孔隙度/% | 声波时差/ (μs·m-1) | 地层电阻率/ (Ω·m) | 自然伽马/ API |
|---|---|---|---|---|---|
| 均值 | 2 515.66 | 20.93 | 189.82 | 8.81 | 132.53 |
| 标准差 | 150.07 | 14.82 | 128.33 | 9.49 | 57.37 |
| 中位数 | 2 526.19 | 16.60 | 162.99 | 4.15 | 121.01 |
| 最小值 | 2 097.80 | 0 | 0 | 0 | 0 |
| 最大值 | 2 954.30 | 63.7 | 691.71 | 44.66 | 293.39 |
| 偏度 | -0.39 | 1.03 | 0.27 | 1.40 | 0.70 |
| 峰度 | 0.07 | 0.48 | -1.64 | 1.37 | -0.005 5 |
本文采用滑动窗口法(Sliding Window Method)进行数据切分(如图1中训练窗口所示),将不同长度的测井曲线数据转化为统一长度的序列数据集,以便开展模型训练。窗口长度由测井数据来源的油藏储层均质性决定。为反映不同深度地层之间的关系,本文实验序列长度为5 m(即每个序列样本包含40个数据点)。由于本文使用的数据集涵盖了来自不同类型油藏的多个油田数据,为确保模型在多样化地质条件下的泛化性和稳定性,数据集划分采用分组抽样的方法。将每个油田中的井按照70%作为训练集、20%作为验证集、10%作为测试集进行随机抽取,最终总体数据集中70%用于训练,20%用于验证,10%用于测试。
2.2 模型训练与参数设置
在训练过程中,盖亚模型的参数设置如表2所示。盖亚模型中解码器主体的参数量为70×108(7 B),适配器模块及其他附加组件的参数量为1.01×108(101 M)。因此,盖亚模型总参数量为71×108(7.1 B),训练参数量的比例为1/70(约1.4%)。训练过程中采用Adam优化器与MAE(Mean Absolute Error,平均绝对误差)损失函数构建基础优化框架,峰值学习率通过循环学习率方法[24]确定。针对模型性能优化需求,设置了动态学习率调度机制:当验证集损失连续5个训练周期未下降时,系统自动按0.9倍衰减学习率,以平衡模型的探索与收敛。训练策略采用序列到序列的范式,通过滑动窗口技术将测井数据切分为序列长度为单位的训练样本,窗口滑动步长与序列长度一致,确保每个窗口内的数据能保持地层连续性。训练过程中,在每个epoch(时期/回合)结束时使用模型在验证集上的损失作为评估标准,以验证集误差最佳的模型权重为最终训练模型的权重,并最终在独立的测试集上进行评估。
表2 盖亚模型的超参数表 |
| 参数 | 设置结果 | 参数 | 设置结果 |
|---|---|---|---|
| 优化器 | Adam | 序列长度 | 40 |
| 损失函数 | MAE | 解码器层数(Decoder Layers) | 32 |
| 最大迭代次数 | 150 | 全连接层数(FC Dimension) | 4 096 |
| 峰值学习率 | 0.000 1 | 注意力头数(Attention Heads) | 32 |
| 学习率调度器的预设因子 | 0.9 | 键/值头数(Key/Value Heads) | 8 |
| 批数量(Batch Size) | 256 | 激活函数 | SwiGLU和GELU |
2.3 实验结果
本文设计并开展了对比实验、消融实验和泛化性实验,如图3所示。对比实验旨在评估盖亚模型在测井曲线重构任务中相较于其他传统深度学习模型及大模型的性能优劣;消融实验旨在量化盖亚模型中各个组件的贡献度及其协同效应;泛化性实验旨在测试模型在未训练区块上的预测有效性。为了实验的公平性,所有对比模型和对比结构均采用与盖亚模型相同的训练超参数。
2.3.1 对比实验
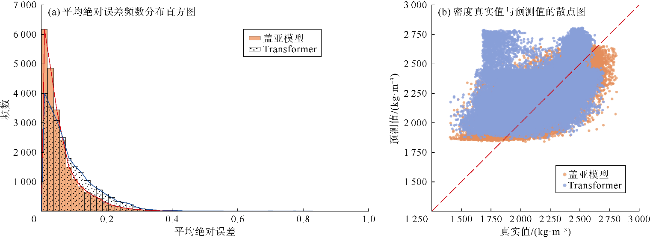
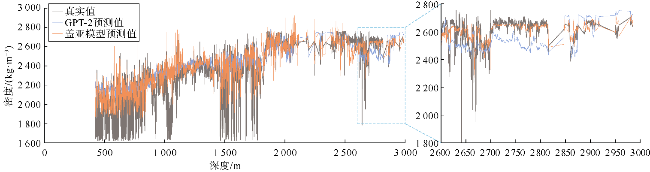
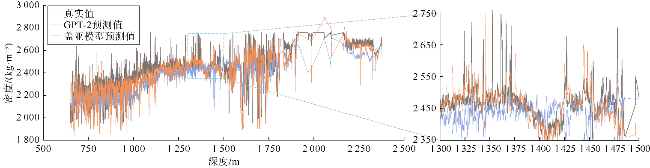
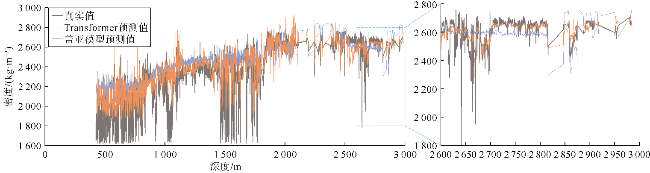
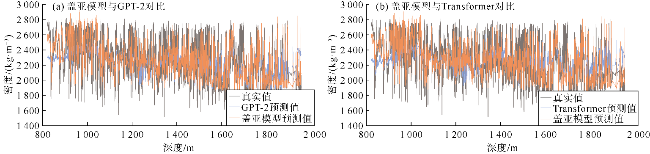
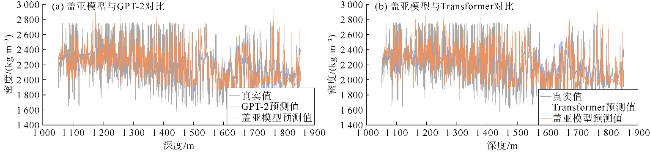
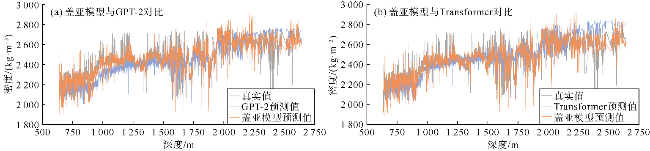
对比实验中,盖亚模型在测井曲线重构任务中展现出显著优势,其在测试集上的均方误差(MSE)相对于Transformer降低了37%、相对于GPT-2降低了48%;平均绝对误差比Transformer和GPT-2分别降低了20%和26%(见表3)。将盖亚模型与Transformer和GPT-2在样本集上的平均绝对误差频数分布进行了对比(见图3a、图4a),靠左侧的频数越高,表明低误差样本越多,模型的预测精度越高。可以看出,相对于Transformer和GPT-2,盖亚模型在低误差区间[0,0.05]中呈现更高的频数,表明盖亚模型的预测结果样本误差相对更小。此外,还对比了盖亚模型、Transformer、GPT-2的预测值与真实值的散点分布情况(见图3b、图4b),散点分布越接近45°对角线说明模型的预测结果越准确。具体的散点密度分布如图5a、图5b、图5c所示,Transformer和GPT-2存在更多远离45°对角线的高预测值区,说明Transformer和GPT-2存在更多预测偏差高的样本群。相对地,盖亚模型在各个区间的预测偏差的区别较小,且盖亚模型的平均绝对误差(MAE)相较于Transformer和GPT-2至少降低了20%,表明盖亚模型具有更高的预测精度。图6—图9的单井实验结果表明,盖亚模型能够更精确地捕捉复杂地层的特征变化,通过预训练的Llama 3.1解码器提取更丰富的序列特征,整体提高了测井曲线重构精度。


2.3.2 消融实验
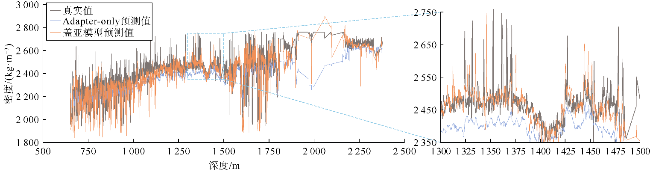
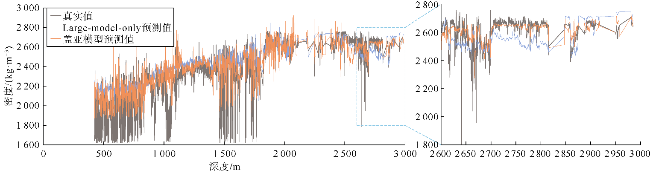
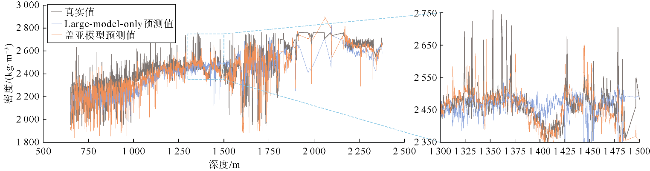
消融实验中,将盖亚模型与Adapter-only结构和Large-model-only结构进行对比,以对比不同模型结构的性能,验证盖亚模型各组件的贡献与协同效果。其中,Adapter-only结构仅使用适配器模块,通过单层的全连接层代替了Llama 3.1的深层解码器,这一结构用于评估盖亚模型中大模型部分对盖亚模型的提升作用,验证适配器模块与大模型预训练的协同效果。Large-model-only结构采用完整的Llama 3.1解码器作为主体,以单层全连接层代替适配器模块。在训练过程中,冻结Llama 3.1解码器的参数进行训练,以评估适配器微调策略对盖亚模型的增益效果。对比结果如图10、图11、表3所示。
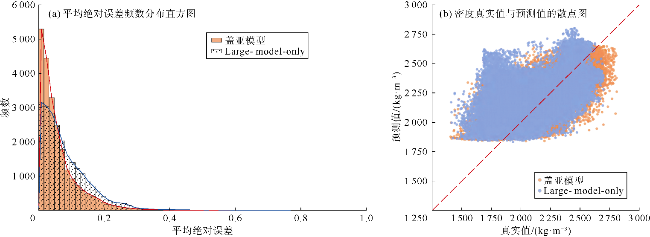

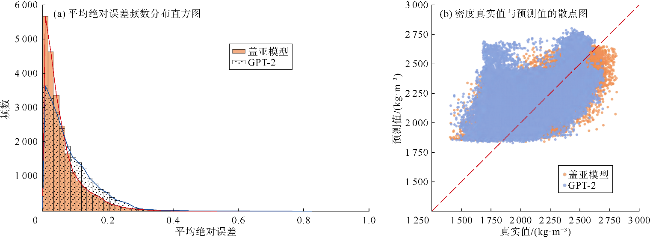
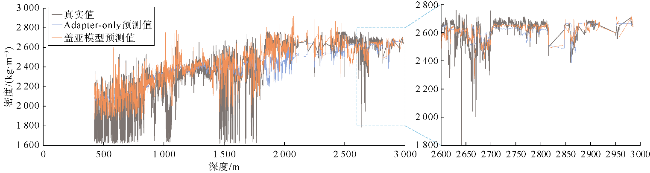
将盖亚模型与Large-model-only结构和Adapter-only结构在样本集上的平均绝对误差频数分布进行了对比(见图10a、图11a)。可以看出,尽管盖亚模型与Large- model-only和Adapter-only结构的样本预测误差频数峰值都在[0,0.05]区间,但Adapter-only和Large-model- only结构在该误差区间内的频数明显低于盖亚模型。因此,大模型主体和适配器模块对盖亚模型性能提升都有正面贡献。图10b和11b对比了盖亚模型、Large- model-only结构、Adapter-only结构的预测值与真实值的散点分布情况,具体的散点密度分布对比如图5a、图5d、图5e所示。散点密度分布图中,Adapter-only和Large-model-only结构表现出多个远离45°对角线的高预测值区。总体上,盖亚模型在测试集上的均方误差分别比Large-model-only结构和Adapter-only结构降低了52%和72%(见表3)。此外,表3显示盖亚模型的平均绝对误差(MAE)较单组件模型至少降低了30%,验证了盖亚模型的多组件协同作用。图12—图15的单井实验结果表明,与盖亚模型相比,两种结构的预测误差较大。综上所述,盖亚模型的预测能力来自各组件的协同效果,删除任何组件都会降低模型效果。具体而言,对于测井曲线重构任务,Adapter-only结构由于缺少大模型主体而准确率不足,这表明预训练大语言模型的参与对于学习复杂地层物理规律发挥着至关重要的作用。盖亚模型中,适配器模块的主要功能是对预训练大语言模型提取的特征进行特征流分配与重新组合。训练适配器的过程,实际上是模型学习将大语言模型提取的信息与目标标签特征进行对齐的过程。从Adapter-only结构的消融实验结果可以看出,大语言模型提取信息为盖亚模型的核心处理能力,对模型准确率提升至关重要。Large-model-only结构由于缺少适配器模块,其准确率同样不足,这表明仅依靠全连接层提取的高维序列特征无法满足盖亚模型对复杂测井曲线重构任务的需求。换言之,尽管大语言模型在预训练阶段已经具备了物理规律推理能力和数学逻辑推理能力,但在缺乏针对性微调策略时,其在测井曲线重构任务上的表现会受到限制。这进一步说明适配器模块在盖亚模型中不可或缺,它通过微调机制将大语言模型的通用知识与测井曲线重构任务的具体需求相结合,从而显著提升模型的性能。
2.3.3 泛化性实验
泛化性实验中,将盖亚模型与Transformer和GPT-2在3组盲井测试实验中的预测效果进行了对比,以评估盖亚模型在未知油田区块上的泛化能力。盲井测试实验采用交叉验证方法,每组实验从加拿大Fox Creek地区油田测井数据集、中国中西部某油田测井数据集以及中国东北部某油田测井数据集这3个具有区域代表性的数据集中选取2个作为训练集,剩余1个作为独立的盲井测试集。由于训练数据集与盲井测试数据集所属区块完全独立,该实验设计能够有效测试模型在未学习邻井地质特征的情况下对盲井进行预测的能力,从而实现对模型泛化性能的完整验证。鉴于各井区数据集所占比例存在差异,为确保训练集、验证集、测试集的比例保持7∶2∶1,实验对盲井测试数据集中的各个区块进行了分层抽样。盖亚模型、Transformer和GPT-2在3组盲井测试实验中的预测值与真实值的散点分布情况如图16、图17所示,具体的散点密度分布如图18—图20所示。
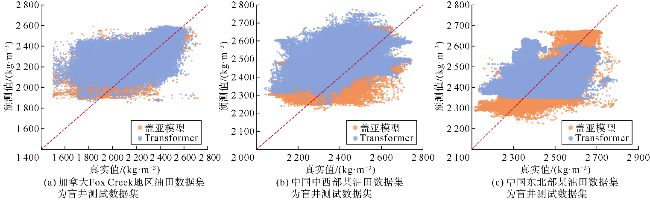
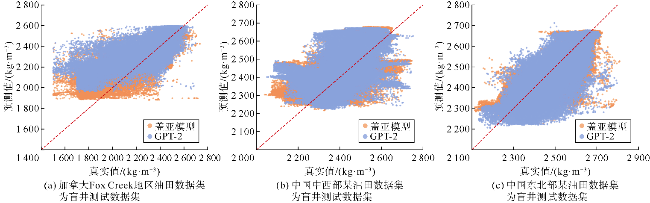
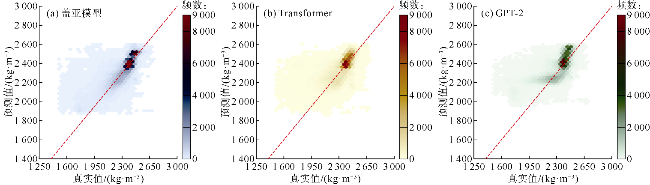
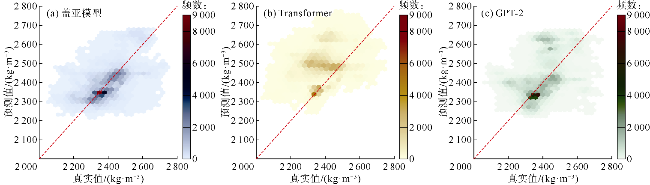
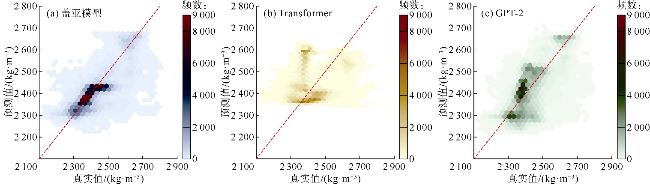
表4 泛化性实验的误差指标 |
| 盲区 | 模型 | 均方误差 | 平均绝对误差 | 均方根误差 |
|---|---|---|---|---|
| 加拿大 Fox Creek 地区 | 盖亚模型 | 0.046 | 0.147 | 0.217 |
| Transformer | 0.215 | 0.379 | 0.464 | |
| GPT-2 | 0.094 | 0.231 | 0.308 | |
| 中国中西部 某油田 | 盖亚模型 | 0.108 | 0.234 | 0.329 |
| Transformer | 0.384 | 0.492 | 0.620 | |
| GPT-2 | 0.209 | 0.342 | 0.457 | |
| 中国东北部 某油田 | 盖亚模型 | 0.280 | 0.313 | 0.529 |
| Transformer | 0.618 | 0.500 | 0.786 | |
| GPT-2 | 0.487 | 0.441 | 0.698 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
表5 跨油藏泛化性实验的误差指标 |
| 井号 | 模型 | 均方误差 | 平均绝对误差 | 均方根误差 |
|---|---|---|---|---|
| 井1 | 盖亚模型 | 0.014 4 | 0.08 | 0.12 |
| GPT-2 | 0.025 6 | 0.12 | 0.16 | |
| Transformer | 0.028 9 | 0.14 | 0.17 | |
| 井2 | 盖亚模型 | 0.014 4 | 0.09 | 0.12 |
| GPT-2 | 0.016 9 | 0.10 | 0.13 | |
| Transformer | 0.019 6 | 0.12 | 0.14 | |
| 井3 | 盖亚模型 | 0.003 6 | 0.04 | 0.06 |
| GPT-2 | 0.008 1 | 0.07 | 0.09 | |
| Transformer | 0.010 0 | 0.08 | 0.10 |
3 结论
本文提出的盖亚模型利用大语言模型的预训练解码器提供通用知识,提升模型对测井曲线序列模式与空间特征的学习能力,从而提升重构精度。该模型采用适配器(Adapter)技术进行微调,仅需重新训练约1/70的参数量,便能精准适配测井曲线重构任务,提高了模型的训练效率,显著降低了模型的应用成本。这种微调大语言模型的模式,使得盖亚模型在测井曲线重构精度和鲁棒性方面均优于常规模型。本文使用的数据集包含不同地区油田250口井的测井数据,为模型的泛化能力提供了有力支撑,避免了针对不同盆地类型反复训练独立模型所带来的高成本和复杂性。在实际应用中,盖亚模型还可扩展至储层评价和地质建模等领域,为油气勘探与开发提供智能决策支持。本文研究的局限性主要体现为数据集的类间样本量差异显著,导致模型对高频油藏类型(如碎屑岩储层)存在过拟合倾向。未来的研究将通过样本平衡策略来解决该问题。同时,考虑引入物理约束方法和多模态建模方法进一步增强模型性能。