

0 引言
根据数据类型可将吉木萨尔凹陷页岩油现场数据资料分为3类:地质、工程和生产数据。这些海量数据离散化严重,直接应用困难,建立数据库能够高效管理并调用数据资料,为压裂参数智能优化提供数据基础。测试产量、首年累计产量及单井预测最终可采储量(EUR)等生产数据通常作为智能模型的优化目标[3]。地质和工程数据需与优化目标建立复杂的映射关系从而优化压裂工艺[4]。精准、高效的映射关系能够准确描述压裂工艺与生产效果间的内在关系。近年来,支持向量机、神经网络、随机森林等智能算法相继用于研究压裂工艺与产量间的关系[5-7]。由于现场数据具有样本少、分布窄、波动大的特点,这些算法的预测能力通常较差[8]。改善数据质量是提升预测能力的有效途径,使用CMG、Petrel等油藏数值模拟软件不仅能扩充样本数量,还能扩大参数取值范围,解决数据集中的问题[9-10]。但这些数据在生成时需进行历史拟合,这一主观过程一定程度破坏了压裂参数与目标变量间映射关系的准确性。同时,大量模拟数据的存在降低了预测模型中现场真实数据的权重,建立的预测模型虽然在数据集中具有较高的预测精度,但与现场压裂的实际结果通常存在一定差异[11]。因此,急需融合领域知识的智能算法来准确描述地质、工程参数与生产能力间的复杂映射关系。遗传算法、粒子群算法等元启发式智能算法由于不需要明确的目标函数[12-13],被广泛用于压裂参数优化,但这些常规优化算法存在全局搜索能力差和易陷入局部最优的缺点,容易导致错过理想的压裂参数。同时,这些算法对于压裂中多维问题的优化效果较差。为解决这些难题,研究者引入特征重要性和主成分分析对其进行降维处理[14-15],但降维后的参数变量牺牲了数据精度且可解释性差。保持压裂效果预测模型的多维特征参数,自适应平衡优化算法在迭代过程中的搜索能力和开发能力对于实现压裂参数多维优化至关重要。
为完善压裂参数智能优化技术,提高吉木萨尔凹陷页岩油压裂改造效果,本文针对储层及开发特点,搭建自治理数据库,建立压裂效果预测模型;在此基础上,迭代联立策略梯度和遗传粒子群算法实现多维参数协同优化,并对比分析该压裂参数智能优化方法的精度和优化能力。
1 自治理数据库搭建及特征分析
1.1 自治理数据库搭建
吉木萨尔凹陷页岩油数据资料来源广、格式复杂,且具有结构化、非结构化数据并存的特点。针对这种多元且复杂的数据特征,本文以油井生命周期为基础,构建了储层、钻井、测井、压裂及生产5大核心表。为实现数据高效治理,配置了各表主外键以唯一标识每条记录并建立表间关联,同时对高频查询字段建立B树索引以提高数据检索速度。具体方法为:利用Python对多元非结构数据进行转换、抓取、清洗,确保数据的准确性与一致性;通过cx_Oracle连接池,帮助数据库客户端有效连接Oracle服务器;设置触发器,实现数据库的自动录入、更新等自治理功能,赋予数据库生命特征。目前,吉木萨尔凹陷页岩油自治理数据库已覆盖油井全生命周期,总计约4 800万条数据。
在规范数据录入、存储工作流的基础上,为增强数据库的应用效果和分析能力,本文基于Django和Vue3技术实现了自治理数据库的高效调用与处理。开发了基于吉木萨尔凹陷页岩油数据库的综合应用平台,该平台集成了数据调用、分析、可视化及用户交互等多项功能,能够更加高效直观地对数据进行分析和处理,为压裂参数智能优化提供了数据基础。
1.2 特征变量筛选及分析
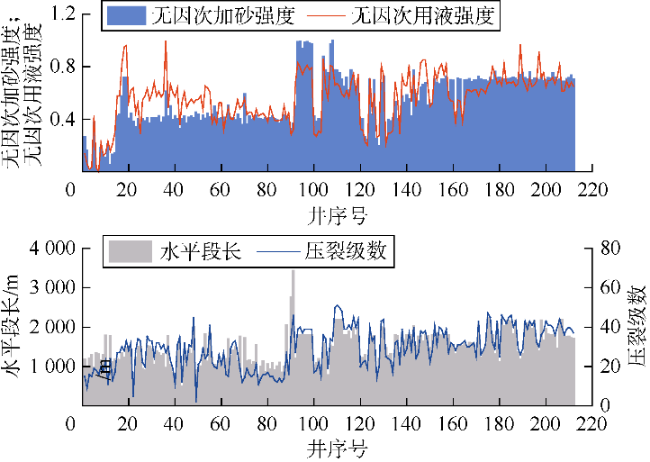
图1为基于自治理数据库整理得到的212口油井部分压裂参数的变化趋势,各油井按照压裂时间先后排序。可以看出第20口井前无因次加砂强度和无因次用液强度(分别为加砂强度、用液强度按最小-最大归一化方法进行归一化后得到)呈现递增的趋势;第20—90口井无因次加砂强度维持在0.4左右,随着材料和技术的进步,后期维持在0.7左右;水平段长和压裂级数呈现出逐渐增大的趋势,第0—90口井水平段长和压裂级数的平均值分别为1 243 m和22,第91—212口井改造长度和压裂级数的平均值分别为1 713 m和35。值得注意的是,第90口井是开发层系调整的转折点,第90口井前主要开发层系为“上甜点”,后期逐渐向“下甜点”进行转移。总的来说,各参数趋势变化明显且关系复杂,综合考虑多因素,全面融合压裂级数、加砂强度及用液强度等特征变量,建立与产能的非线性复杂映射关系,对提升压裂参数的智能优化能力至关重要。
经特征工程和数据分析后,基于数据完整度和生产匹配性,本文筛选出7个地质参数、3个钻井参数和12个压裂参数作为后续压裂效果预测模型的特征变量(见表1)。其中,x、y坐标为页岩油井的井口坐标(向北x为正,向东y为正),深度为水平段的平均深度;钻遇率表征油井水平段的储层“甜点”钻遇情况,Ⅰ类钻遇率、Ⅱ类钻遇率分别表征油井水平段的Ⅰ类、Ⅱ类储层钻遇情况。
表1 特征变量统计表 |
| 类型 | 特征变量 | 符号 |
|---|---|---|
| 地质参数 | 改造层位 | L |
| 渗透率 | K | |
| 孔隙度 | ϕ | |
| 含油饱和度 | So | |
| x坐标 | x | |
| y坐标 | y | |
| 深度 | D | |
| 钻井参数 | 钻遇率 | Rc |
| Ⅰ类钻遇率 | RC1 | |
| Ⅱ类钻遇率 | RC2 | |
| 压裂参数 | 加砂强度 | Sp |
| 用液强度 | Sf | |
| 小粒径支撑剂占比 | Zs | |
| 大粒径支撑剂占比 | Zl | |
| 低黏度流体占比 | Fl | |
| 高黏度流体占比 | Fh | |
| 泵注排量 | Q | |
| 簇间距 | Cs | |
| 关井时间 | Ts | |
| 压裂液类型 | Sf | |
| 暂堵剂用量 | Pt | |
| 压裂级数 | S |
注:各变量均取按最小-最大归一化方法处理后的无因次量 |
由于缺乏足够的光纤监测数据,本文以油井归一化EUR作为压裂参数的优化目标,该归一化EUR为页岩油井单位改造长度EUR按最小-最大归一化方法进行归一化处理的结果。计算了各特征变量及归一化EUR共计23个参数两两之间的皮尔逊相关系数,结果表明:加砂强度与用液强度、高黏度流体占比均具有显著的相关性,相关系数分别为0.82和0.79,高加砂强度需要更多、更黏的滑溜水才能实现有效携砂,以防发生砂堵风险;泵注排量与压裂液类型的相关系数为0.73,相对于胍胶,滑溜水具有低摩阻、低黏度的优势,相同设备下滑溜水的施工排量更高;深度与y坐标的相关系数为−0.77,这符合吉木萨尔凹陷二叠系芦草沟组东高西低的构造特征;由于吉木萨尔凹陷储层较为致密,较高渗透率区域能够显著增强油气的渗流能力,使得特征变量中渗透率与EUR的相关性最大,相关系数为0.56。
2 压裂效果预测模型
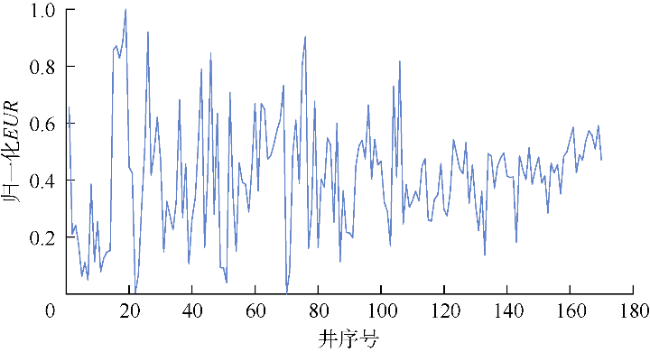
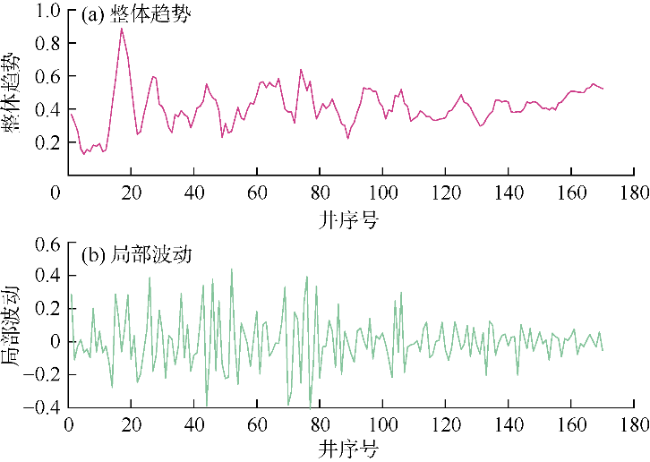
吉木萨尔凹陷页岩油EUR压裂学习曲线能够反映储层认识和压裂技术的迭代升级过程,但其具有体量小、波动大的特点。机器学习算法对于这类小样本且波动剧烈的数据预测效果较差。为了准确预测目标变量,本文提出分离式压裂效果预测模型TgDD,将EUR压裂学习曲线分解为整体趋势和局部波动两部分,即:
2.1 整体趋势预测模型
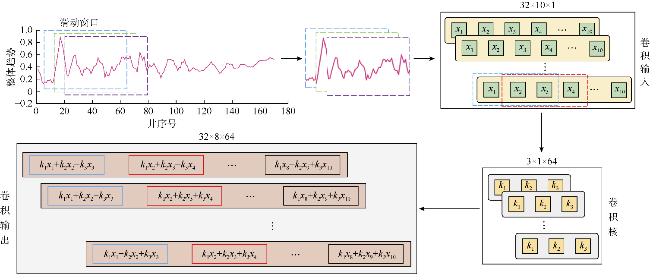
整体趋势反映吉木萨尔凹陷页岩油压裂效果的整体特征,具有一定的周期性和规律性,体现了先验知识的作用,对其进行精准预测能够帮助预测实际EUR。本文结合卷积神经网络(CNN)局部连接和参数共享的特点以及门控循环单元(GRU)能够解决梯度消失的优势,建立CNN-GRU算法对整体趋势进行预测。该方法可减少计算量,节省模型训练时间。基于CNN-GRU算法的整体趋势预测模型结构如图4所示。该模型以整体趋势作为CNN的输入,经贝叶斯优化后使用大小为10的滑动窗口对整体趋势进行切片处理,利用CNN中卷积层的特征提取能力,在输入的整体趋势中提取出一组序列化特征向量,该特征向量经全连接层调整至GRU的输入尺寸。GRU提取该特征向量的时间维度信息后传输至新的全连接层,新的全连接层通过权值矩阵对所有特征信息进行整合,最终输出整体趋势的预测结果。
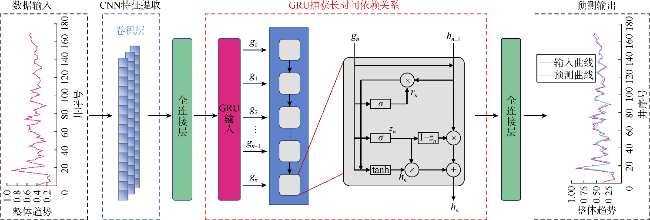
模型中CNN部分包含1个卷积层(见图5)。该卷积层具有64个卷积核,卷积核的大小为3×1。考虑到模型的输入特征,模型中卷积层的输入尺寸设计为32×10×1,输出尺寸为32×8×64。模型中的GRU部分设置了50个单元。模型的所有模块均选用ReLU(线性整流函数)作为激活函数。
2.2 局部波动预测模型
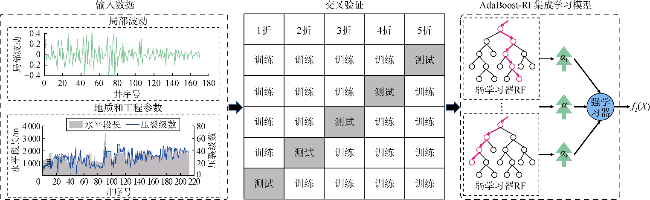
自适应增强算法(AdaBoost)是一种采用Boosting策略的集成学习算法[18]。本文使用AdaBoost集成随机森林算法(RF),建立AdaBoost-RF算法对局部波动进行预测,模型示意图如图6所示。首先对地质、工程参数和局部波动数据进行第1轮RF训练,训练过程中每个样本权重相同,从而得到第1个弱学习器RF。再对第1轮训练过程中被分错的样本的权重进行调整得到新的样本,并且根据错误率调整新样本的权重,从而得到另一个弱学习器RF及其权重。按照这个步骤,进行k轮训练,得到k个弱学习器RF。然后,将这k个弱学习器RF使用AdaBoost构造成一个强学习器。最后,利用这个集成学习的强学习器建立地质、工程参数与局部波动间的映射关系,得到局部波动的预测结果。模型中,5折交叉验证被用于对数据集进行划分和预测,即将数据集随机均分为5个互斥的子集,在每折预测中选择1个子集作为测试集,剩余4个子集作为训练集,重复5次,预测误差取5次测试的平均值。
2.3 压裂效果预测结果
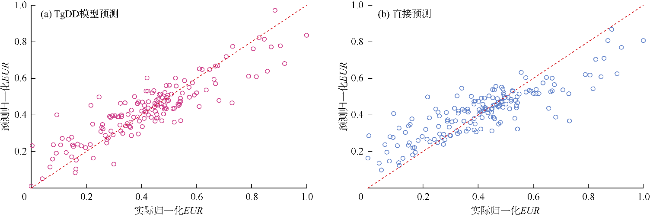
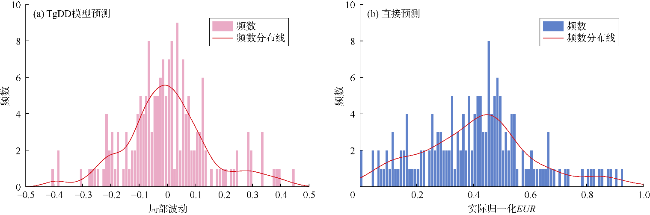
在分别实现整体趋势和局部波动的预测后,联立计算吉木萨尔凹陷页岩油井的EUR。图7a为TgDD模型在测试集中对EUR的预测结果,可以看出几乎所有数据均位于对角线附近,且实际EUR和预测EUR在整个区间的分布特征呈现出较好的一致性,这表明TgDD模型具有较好的预测能力。作为对比,采用本文建立的AdaBoot-RF算法直接预测EUR,预测结果如图7b所示。可以看出,直接预测时实际EUR和预测EUR同样聚集在对角线附近,但其预测能力显著低于TgDD模型:在实际EUR较小和较大时,预测EUR分别集中位于对角线上部和下部,这表明直接预测时对较大和较小EUR的预测能力较差。图8为局部波动和EUR的分布特征,可以看出:将EUR分解为整体趋势和局部波动后,得到的局部波动具有较强的聚集性,这极大提升了预测模型目标变量的数据质量,使得TgDD模型具有较高的预测精度;未经处理的EUR在整个区间分布较为离散,以其直接作为预测模型中的目标变量时,智能算法对这类数据的预测能力相对较差。
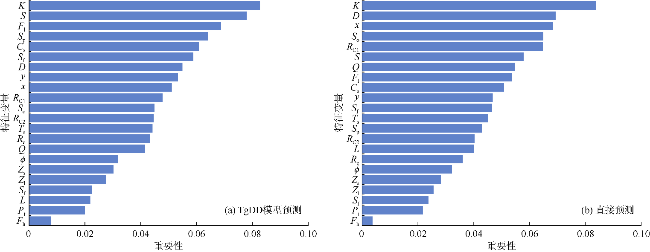
AdaBoost-RF以RF作为弱学习器,能够量化特征变量的重要性。图9为直接预测和TgDD模型中的特征变量重要性分布。直接预测时,前4个最重要的特征变量均为地质参数,因为地质属性是至关重要的参数,决定了储层的质量和开发难度。压裂参数中压裂级数、泵注排量、低黏度流体占比、簇间距、用液强度对预测模型的贡献程度较大,这几个参数决定了压裂过程中人工裂缝在储层中的复杂程度。加砂强度对预测模型的贡献程度较小,这是由于吉木萨尔凹陷页岩油实际压裂参数中用液强度与加砂强度具有显著共线性,使用用液强度来训练预测模型时,已充分考虑加砂强度对EUR的影响。与直接预测相比,TgDD模型中特征变量重要性分布有所变化,主要表现为地质参数重要性降低,低黏度流体占比、加砂强度等压裂参数重要性显著提高。这是因为压裂学习曲线滤波后的整体趋势反映了储层认识、工艺技术逐渐成熟的变化,而局部波动更能反映压裂参数对产能的影响。值得注意的是,渗透率在TgDD模型预测和直接预测时均是最重要的影响参数,这是因为EUR与渗透率具有较高的相关性。高黏度流体占比、暂堵剂用量、大小粒径支撑剂占比和孔隙度对预测模型的贡献程度较小。这是因为,吉木萨尔凹陷页岩油压裂初期压裂液主要为胍胶和胍胶+滑溜水体系,后期完全替换为滑溜水体系时才出现高黏度流体占比这一参数;前期压裂时几乎不添加暂堵剂,仅在压裂后期不到30%的压裂井使用了暂堵剂;现场压裂中小粒径、中粒径和大粒径支撑剂的比例几乎均为1∶3∶6,大、小粒径支撑剂占比这两个参数几乎无变化;吉木萨尔页岩较为致密,孔隙度波动小。这些参数均是由于数据质量较差,导致预测模型难以准确识别其与EUR的映射关系。
TgDD模型预测和直接预测的均方误差分别为0.008 4和0.012 4,即本文建立的TgDD模型对EUR的预测精度比直接预测提升了47.6%。这是因为,TgDD模型由整体趋势预测模型和局部波动预测模型两部分组成。一方面,时序数据压裂学习曲线滤波后的整体趋势仍属于时序数据[17],建立的CNN-GRU算法对其具有极强的预测能力,均方误差仅为0.001 7。另一方面,处理后的局部波动数据聚集程度显著增强,相对于EUR,局部波动具有更高的数据质量,以局部波动作为目标变量的均方误差为0.007 7,与直接预测相比精度提升了61.1%。
3 压裂参数智能优化方法
TgDD模型为黑盒模型,理论上穷举所有压裂参数并调用模型能够实现压裂参数优化工作。但实际施工中压裂参数取值无穷无尽,针对这一难题,本文采用元启发式优化搜索算法,利用随机化和群体协作来迭代搜索最优解,该算法不需要明确的目标函数,能够协同压裂效果预测模型取得较好的优化效果。
3.1 策略梯度-遗传-粒子群优化算法
本文提出一种策略梯度-遗传-粒子群优化算法(PGGAPSO)来进行压裂参数优化,该算法结合了粒子群优化(PSO)算法、遗传算法(GA)和策略梯度(PG)算法等。
在粒子群优化算法中,问题的候选解表示为粒子,在压裂参数优化问题求解过程中每个粒子均对应1个EUR值。混沌映射产生的混沌序列具有非线性、遍历性、随机性、不可预测性等优点,使用混沌映射对粒子进行初始化能够增强粒子群算法的优化性能[19]。因此,本文使用Logistic混沌映射对粒子群算法进行初始化。同时,本文采用全连接的拓扑结构,在每次迭代过程中,粒子通过跟踪历史最优解和全局最优解来更新速度和位置[20]。粒子群算法容易搜索不彻底从而错过问题的最优解。鲸鱼优化算法是Mirjalili等[21]参照座头鲸群体行为捕食习性提出的元启发式优化搜索算法,该算法具有全局搜索能力强的特点。因此,对于EUR值较低的非精英粒子,本文使用鲸鱼优化算法中包围搜索和螺旋搜索策略帮助粒子在全局最优解附近进行搜索,而精英粒子则继续使用粒子群搜索策略。
策略梯度算法是一种基于策略迭代的强化学习算法,通过构建一个策略神经网络对粒子群算法参数进行自适应调整,输入为智能体观测到的状态,输出为动作概率分布[23]。策略梯度算法与粒子群优化算法存在某种相似性,粒子群优化算法的寻优方向与策略梯度算法中损失函数对网络参数的梯度相似,均决定了策略的更新方向。策略神经网络的参数更新过程与粒子群优化算法中粒子速度和位置的更新过程相似,均是在上一次迭代的基础上实现本次的参数更新。
基于策略梯度算法与粒子群优化算法之间的联系,本文提出了PGGAPSO算法,该算法通过构建1个策略神经网络与遗传粒子群(GAPSO)进行交互学习,对GAPSO中的惯性权重和学习因子进行自适应调整(见图10)。PGGAPSO主要可分为3个部分:智能体与环境的动态交互、智能体的内部结构和GAPSO的参数更新。
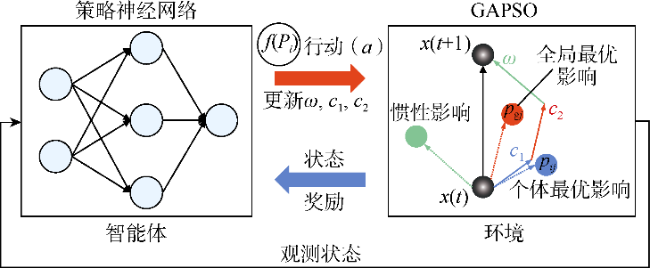
智能体与环境之间的交互以策略神经网络为强化学习智能体,以整个GAPSO为学习环境。状态设置为:GAPSO中粒子的位置和速度、惯性权重(ω),学习因子c1和c2,粒子的历史最优位置和全局最优位置;动作设置为:六维动作空间,由策略神经网络输出的动作概率分布(P0,P1,P2,P3,P4,P5)所确定;奖励设置为:粒子群优化算法此次迭代与上一轮迭代计算得到最优EUR的差值。
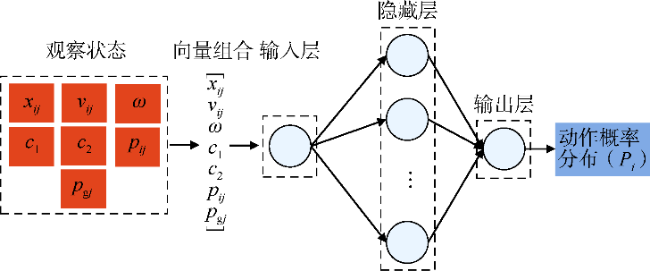
PGGAPSO算法中智能体的内部结构为1个策略神经网络(见图11)。策略神经网络的输入为七维状态观察空间,输出为六维动作概率分布,其隐藏层选用tanh作为激活函数。通过最小化损失函数L(θ)来更新策略神经网络参数。
对于GAPSO的参数更新过程,PGGAPSO利用所设计的策略神经网络和动作选择函数,实现惯性权重和学习因子的自适应调整,有效降低经验配置参数导致的误差。参数具体更新规则如表2所示。
表2 参数更新规则 |
| a | ω | c1 | c2 |
|---|---|---|---|
| 0 | ω=ω+0.01 | ||
| 1 | ω=ω−0.01 | ||
| 2 | c1=c1+0.01 | ||
| 3 | c1=c1−0.01 | ||
| 4 | c2=c2+0.01 | ||
| 5 | c2=c2−0.01 |
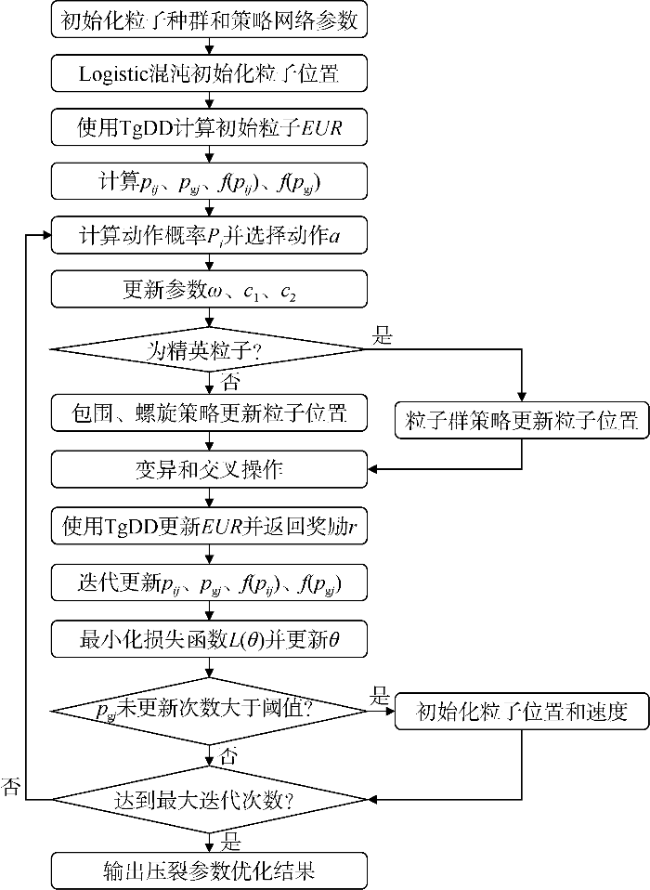
本文提出的PGGAPSO算法流程图如图12所示。首先根据EUR大小对精英粒子进行判定,对精英粒子和非精英粒子分别采用不同的位置和速度更新策略。随后使用遗传算法对粒子的位置进行变异和交叉操作,最后使用策略梯度对粒子群优化中的惯性权重和学习因子进行自适应调整,从而影响迭代中精英粒子位置和速度的更新方式。
3.2 压裂参数优化结果
采用PGGAPSO算法对第171口井压裂参数Sp、Sf、Zs、Zl、Fl和Fh进行优化。PSO、GA、量子行为粒子群算法(QBPSO)、GAPSO和自适应粒子群算法(ACPSO)被用于进行对比分析。图13为各优化算法10次迭代过程的平均值。引入变异和交叉操作后,全局搜索和跳出局部最优的能力显著增强,促使GAPSO和PGGAPSO的EUR在收敛后期明显优于其他算法。收敛初期由于样本数据较少,PGGAPSO中深度学习模块学习能力较弱,导致其收敛能力略低于GAPSO。随着持续迭代,强大的深度学习模块使PGGAPSO在收敛后期展现出极强的优化能力。PG模块能够自适应调整惯性权值和学习因子,使粒子在不同阶段具备更好的搜索策略。与其他算法相比,PGGAPSO在搜索过程能够很大程度避免陷入局部最优,其优化能力明显强于非强化学习算法。
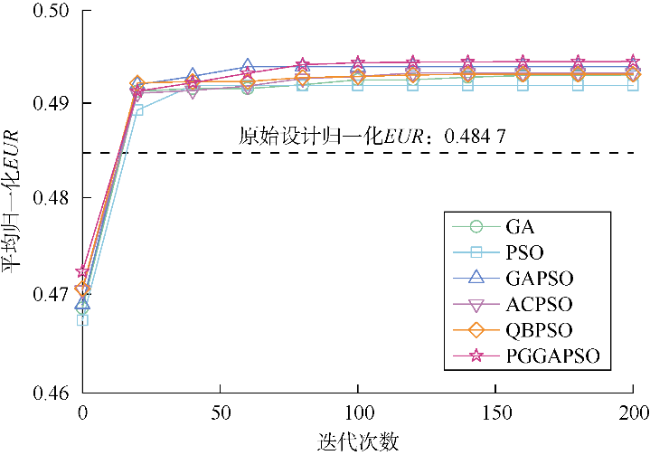
表3为各优化算法10次迭代过程的统计情况。PGGAPSO的优化能力最强,GAPSO优化能力次之,PSO表现最差。原始压裂设计对应的归一化EUR为0.484 7,PGGAPSO和PSO对归一化EUR进行优化后的最大值分别可达0.495 1和0.492 9,对应可将压裂效果提升2.15%和1.69%。也就是说,相对于PSO,PGGAPSO的优化能力增强了27.2%。
表3 各优化算法对第171口井归一化EUR的优化结果 |
| 算法 | 平均值 | 最小值 | 最大值 | 标准差 |
|---|---|---|---|---|
| PGGAPSO | 0.494 5 | 0.493 2 | 0.495 1 | 4.21×10-4 |
| GAPSO | 0.493 4 | 0.491 9 | 0.493 7 | 4.63×10-4 |
| ACPSO | 0.493 2 | 0.491 5 | 0.493 8 | 4.79×10-4 |
| QBPSO | 0.493 1 | 0.491 3 | 0.493 5 | 5.53×10-4 |
| PSO | 0.491 9 | 0.490 7 | 0.492 9 | 6.12×10-4 |
| GA | 0.492 9 | 0.491 7 | 0.494 4 | 5.31×10-4 |
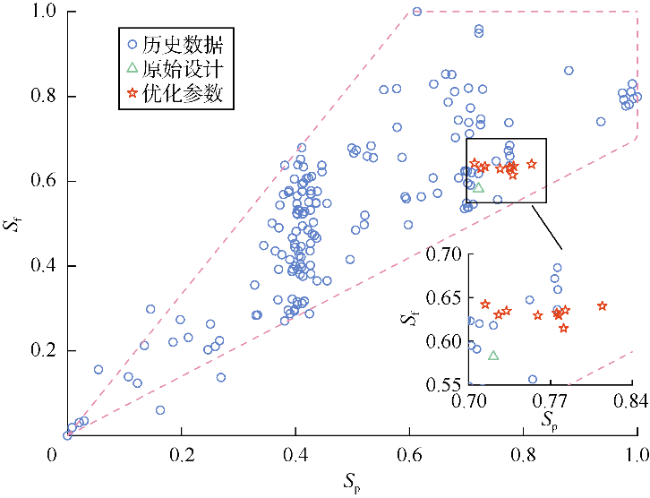
第171口井压裂参数Sp、Sf、Zs、Zl、Fl和Fh的原设计归一化值分别为0.721 3,0.582 4,0.545 3,0.556 7,0.592 5,0.355 9。使用PGGAPSO优化后EUR最大值对应的上述压裂参数归一化值分别为0.759 2,0.629 6,0.623 1,0.514 7,0.652 7,0.336 7。图14为10次PGGAPSO优化后的加砂强度和用液强度的分布。对于该井而言,原始设计中加砂强度和用液强度偏小,增加施工强度能够一定程度增加油气的采出程度。
4 现场应用
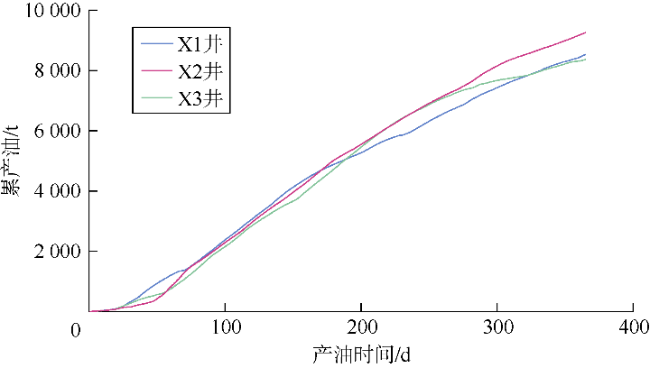
吉木萨尔凹陷X2井的压裂级数为30,平均簇间距约8.1 m。采用本文压裂参数智能优化技术对其压裂参数进行优化的结果为Sp=0.712 3,Sf=0.792 4,Zs=0.566 2,Zl=0.540 3,Fl=0.652 7,Fh=0.399 2。X1、X3井与X2井相邻,其开发层位、压力系数、射孔完井工艺等均与X2井相同。不同的是,X1、X3井均使用专家经验对压裂参数进行设计,设计结果为Sp=0.707 3,Sf=0.772 8,Zs=0.545 5,Zl=0.555 7,Fl=0.629 3,Fh=0.481 8。这3口井在压裂后均立即焖井30 d。图15为投产后1年内各井的累计产油量曲线。生产1年后,X2井累计产油9 259 t,X1、X3井累计产油量分别为8 532 t和8 369 t。所有井生产过程中日产水持续下降未对产油造成影响。相对于X1、X3井,生产1年后X2井累产油平均提升了10.1%。由此可见,采用压裂参数智能优化技术优化X2井的压裂参数效果显著。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
5 结论
本文针对吉木萨尔凹陷页岩油储层搭建了自治理数据库对数据进行规范管理与特征分析,完善了智能预测模型和优化模型,并实现了多参数协同迭代优化过程,提出了一套压裂参数优化智能方法。
压裂学习曲线能够客观反映压裂改造规律,建立了以整体趋势和局部波动为目标变量的TgDD预测模型。该模型利用CNN-GRU算法捕捉时序数据内部特征的同时,提升了现场地质和压裂数据的质量,从而大幅增强压裂效果的预测能力。相比直接使用AdaBoot-RF算法,其预测精度提升了约47.6%。
GA的引入能够协助粒子跳出局部最优解。强化学习模块在迭代过程中能够自适应调整惯性权重和学习因子,显著增强了粒子的全局搜索能力。PGGAPSO与TgDD结合后能够更好地捕捉优化方向,高效优化多压裂参数,其优化能力相比PSO提高了27.2%。经现场试验验证,该方法对油井压裂效果提升显著,具有较好的实用性。
符号注释:
c1——个体学习因子;c2——全局学习因子;gn——GRU输入;f(X,T)——EUR压裂学习曲线;f1(T)——整体趋势;f2(X)——局部波动;f(Pi)——行动选择函数;hn-1——上时刻数据状态;hn——当前时刻数据状态;k——弱学习器序号;k1,k2,k3——卷积核的权重;pgj——第j维的全局最优位置;pij——第i个粒子在第j维的历史最优位置;Pi——行动概率;x(t),x(t+1)——粒子在t时刻和t+1时刻的位置;rn——GRU重置门;n——时间步序号;T——无因次时间;vij——第i个粒子在第j维的速度;x1,x2,…,x10——整体趋势数据切片;xij——第i个粒子在第j维的位置;X——无因次特征参数;zn——GRU更新门;tanh——双曲正切函数;α——弱学习器的系数;α1——第1个弱学习器的系数;αk——第k个弱学习器的系数;σ——Sigmoid函数;ω——惯性权重。