

0 引言
截至2023年底,美国和中国发布的通用大模型总数占全球发布量的80%,成为大模型技术领域的引领者。国外通用大模型以Open AI公司的GPT、微软公司的PaLM和Meta公司的LLaMA为代表[7⇓⇓⇓⇓⇓-13],其中LLaMA系列属于开源大模型。中国百度文心一言、阿里云通义千问、腾讯混元、百川智能Baichuan系列、清华大学GLM-130B等大模型独占鳌头[14⇓⇓-17]。斯坦福大学基于LLaMA大模型进行微调得到了羊驼(Alpaca)大模型。在评估中,Alpaca7B模型在Self-Instruct指令评估上的表现堪比GPT-3.5模型[18]。Chinese-Alpaca-2.0在Alpaca模型的基础上用大规模中文语料进行了增量预训练,进一步提升了模型的中文对话能力。然而,通用大模型在特定领域专业性不足,缺乏对专业知识和术语的深入理解能力。因此,在通用大模型的基础上借助专业词表扩充和增量预训练的方法可使通用模型进一步适用于如金融、法律、医疗或油气勘探开发等特定行业。
本文针对油藏动态分析智能化需求,提出了一种场景大模型构建方法及关键技术,利用命名实体识别(NER)技术实现并测试了油藏动态分析中的子任务识别功能;基于Text-to-SQL(自然语言转换成结构化查询语言)实现并测试了油藏静态资料、动态数据的查询功能;基于分类任务实现并测试了公式计算及商业软件使用等辅助功能;依托行业大模型融合油藏静态资料、动态数据查询和计算结果等信息,实现了油藏动态问题的分析与建议功能。本文首次将人工智能大模型初步应用到油藏动态分析领域,为大模型在油藏动态分析中的运用提供了可行的技术方案,一定程度上简化了从业人员在油藏动态分析场景中与大模型的人机交互流程。
1 油藏动态分析场景大模型构建思路
构建油藏动态分析场景的大模型,首先必须建立以石油工程专业知识为核心的行业大模型,然后针对场景中特定任务,通过微调来优化模型,以确保其能够精确地解决垂直领域的具体问题。因此构建油藏动态分析场景大模型分为增量预训练、子系统指令微调与功能子系统耦合3个步骤(见图1 )。增量预训练完成通用基础大模型优选和预训练数据集准备,并在扩充通用大模型专业词表的基础上,使用相关数据集对其进行增量预训练获得用于后续研究的石油工程行业大模型。子系统指令微调从分析建议、数据检索、工具分类3种任务需求出发,微调出3种具有针对性应答能力的模型。功能子系统耦合为3种微调模型拟定数据流输入输出接口,并基于特定的逻辑关系对3种微调模型进行耦合形成能够满足油藏动态分析场景需求的3个功能子系统。

1.1 增量预训练
鉴于当前暂未有可用于学术研究的开源油气行业大模型,本文基于Chinese-Alpaca-2.0(开源中文大模型)构建了用于后续场景大模型应用研究的石油工程行业大模型。具体步骤包括扩充0.7 kB常用专业词表、使用收集整理的约8.5 GB石油工程文献/书籍等无标签数据集进行增量预训练。由于增量预训练对数据源有较高要求,本文构建用于研究的石油工程行业大模型在性能与经济性上有所折中。
预训练数据集涵盖了油气藏开发工程、地质勘探、钻井工程、压裂工程的专业文献、书籍以及相关软件帮助文档。以下为借助Python相关工具包提取和整理PDF文件数据的过程:使用PyPDF2工具包区分文档及图像类PDF,借助Tesseract-OCR工具包将所有图像类PDF转化为文档类PDF,采用Grobid工具包将文档类PDF转化为XML/TEI(可扩展标记语言/文本编码规范)编码文件,使用LXML工具包中的Etree模块读取并按段落切分所有XML/TEI编码文件,使用XML2MD工具包将切分后的文件转化为Markdown轻量标记的文本格式,最后获得共计约8.5 GB的增量预训练数据。同时,本文收集专业词汇并参照增量预训练数据内容进行筛选,在Chinese-Alpaca-2.0的55 kB基本词表基础上扩充了0.7 kB 专业词汇,以确保用于本文的石油工程行业大模型能够更准确地识别石油工程专业术语,并在分词过程中对专业词汇进行恰当分割。
专业词表拓展后,分词器对专业“元素”进行了保留,使大模型能在增量预训练过程中从相关领域的语料中更准确地捕捉到上下文中专业信息间的序列关系。
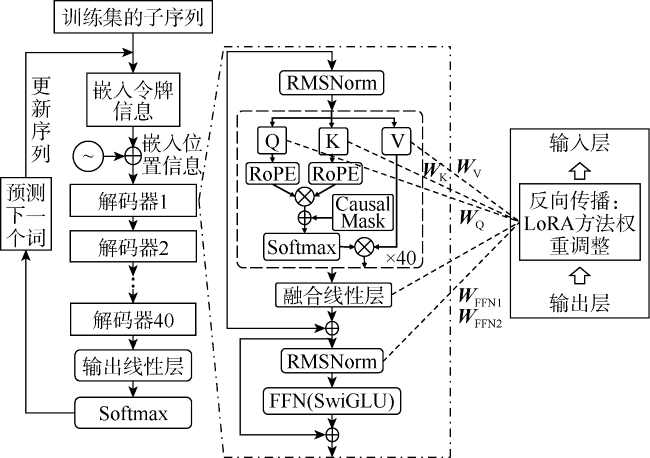
本文采用的Chinese-Alpaca-2.0(13 B)由40层Transformer decoder叠加,每个解码器中的self- attention(自注意力机制)又包含40个注意力层,每个自注意力层有4个权重矩阵,分别为(WQ,WK,WV,WO),其中WO为输出层权重矩阵,MLP(多层感知器)由两层FNN构成(WFNN1,WFNN2)。在增量预训练每次反向传播的过程中,涉及6 480个权重矩阵的权重调整,其中WQ、WK、WV、WO矩阵共计6 400个,WFNN1、WFNN2矩阵共计80个。权重调整采用LoRA方法[24],该方法可为现有权重矩阵增加一个旁路,在训练过程中固定通用基础模型的所有权重参数,只训练降维矩阵与升维矩阵即可,这将显著减少在反向传播中所需调整的权重数量。
1.2 子系统指令微调
油藏动态分析场景大模型通过混合专家系统的构建方法实现,这种通过程序设计混合并充分发挥多模型能力的方法在特定场景下的大模型应用中已较为普遍[25]。油藏动态分析场景大模型是将分别擅长于分析建议、数据检索、工具分类3种特定任务模式的微调模型A、B、C联合使用,并借助特征提取模型D从用户输入中获取多维度实体信息,规划A、B、C的具体调用方案,实现4种综合场景应用功能:①分析解答油藏动态分析场景问题;②查询油田动静态数据库,挖掘数据变化规律;③调用工具进行油田现场开发指标计算;④联动分析涉及场景①—③的复杂混合问题。
油藏动态分析场景大模型中总共包含4种微调模型,4种模型分别使用不同的标签数据集,基于这些数据在石油工程行业大模型基础上通过LoRA方法微调获得。其中分析建议模型、数据检索模型、工具分类模型面向特定场景微调,特征提取模型主要用于对用户输入进行特征提取。
由于模型A、B、C均接收自然语言输入,输出为Markdown轻量文本标记格式,而计算机程序模块的耦合通常借助函数调用的方式,因此A、B、C分别被封装到油气藏工程复杂问题建议系统(系统Ⅰ)、数据挖掘与动态规律分析系统(系统Ⅱ)、工具集成调用系统(系统Ⅲ)3个子系统中,以便为不同系统指定不同的参数调用接口与返回值,确保系统间的可编程耦合。系统中则可将函数输入参数和变量混合成JSON(JavaScript对象表示法)字符串的格式作为大模型的提示词。这种混合提示词的方法[26]可让各系统对模型的使用更加灵活,实现单模型多用途的效果。
①油气藏工程复杂问题建议系统(见图3 )在回答一般油气工程问题时,直接调用行业大模型回答,并将结果传到输出接口1;在回答单井动态、井组注采动态分析、区块动态分析相关的油藏动态分析具体场景问题时,使用JSON混合用户问题、系统Ⅱ输出的动静态数据资料、系统Ⅲ输出的外部工具调用结果构成混合提示词交由模型A回答,并将结果传到输出接口2。
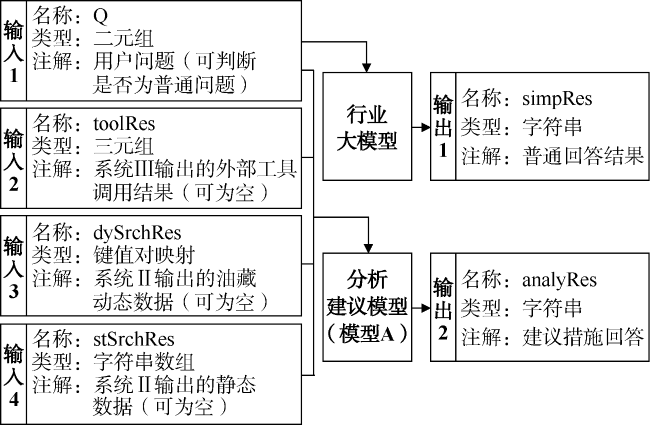
②数据挖掘与动态规律分析系统(见图4 )依托模型B的Text-to-SQL功能完成对自然语言到SQL(结构化查询语言)检索语句的转换,利用转换得到的SQL语句完成在数据库中的查询,并将查询结果传到输出接口1与2,输出查询的油藏动静态数据。另外,当需要对数据进行趋势分析时,查询的数据结果将交模型A完成趋势分析,并将分析结果传到输出接口3。

③工具集成调用系统(见图5 )中各种工具的API(应用程序编程接口)调用方法预先编写在不同函数中,通过模型C将含有工具种类信息的相关描述转化为特定分类编号,完成对应工具的查询和调用,并结合系统Ⅱ输出的动静态数据,对动态分析中的相关开发指标进行计算。为兼顾工具调用时输入输出数据的柔性与大模型的可读性等需求,本文外挂工具服务的输入输出流均统一为JSON字符串格式。
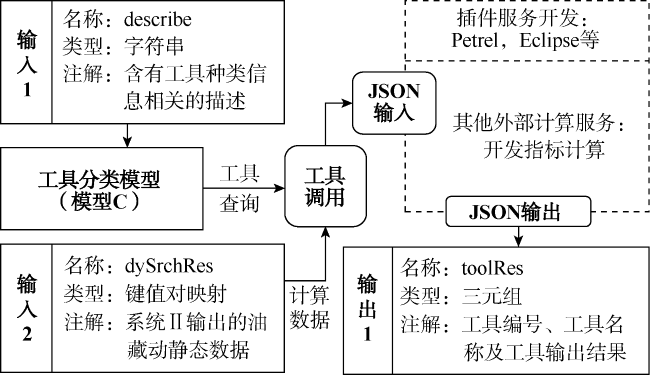
为保证工具调用的独立性与可扩展性,本文中不同的外部工具系统均独立搭建,并通过RPC(远程过程调用)协议和RESTful接口(基于表述性状态转移架构风格的网络服务接口)实现API调用。例如,在开发Petrel插件服务时,可通过Petrel SDK(软件开发工具包)实现特定功能,如连井剖面绘制服务等。该服务接受模型名称、井号作为请求参数,调用Petrel SDK接口通过井号获取井坐标,后基于两井坐标绘制井间剖面,再将生成的图像保存到文件服务器,并将文件资源路径和连井间地层属性数据保存为JSON返回。
1.3 功能子系统耦合
在油藏动态分析场景大模型中,特征提取模型D的输出结果直接影响到本轮用户问答中油藏动态分析场景大模型对系统Ⅰ,Ⅱ,Ⅲ的调用情况。为实现油藏动态分析场景大模型子系统间的集成与协同,本文提出了一种功能子系统耦合方法(见图6 )。
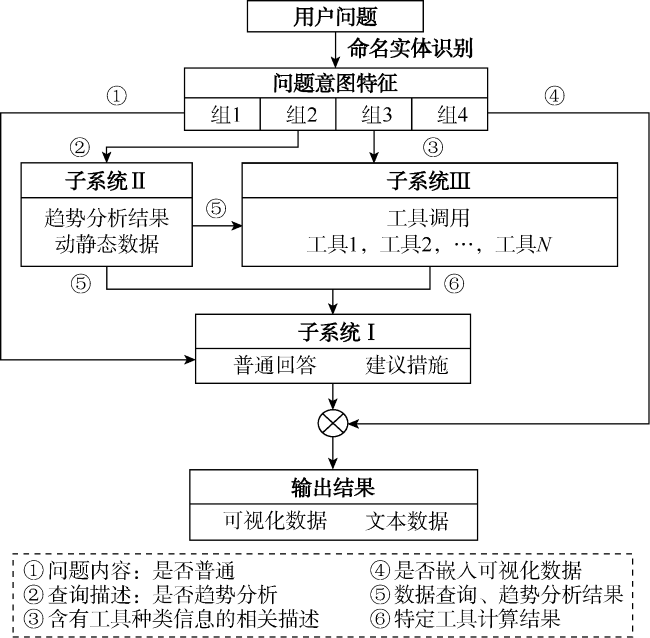
油藏动态分析场景大模型首先通过命名实体识别对用户问题进行细致分解,提取实体和对问题进行更深层次的语义分析,并将用户问题意图特征分为4组,如普通问题问答、数据检索分析、计算需求或分析建议。针对普通问题,将直接交由系统Ⅰ进行问答回复;针对数据检索需求,模型通过系统Ⅱ中的Text-to-SQL功能查询数据库中相关数据;针对计算需求或分析建议,模型通过系统Ⅲ中的外部工具调用功能实现本文相关技术指标的单独计算并调用Petrel绘制相关图件。最后用户问题的所有请求和回答结果将由统一的前端页面进行可视化处理,包括可视化数据和文本数据。
该方法在确保各子系统独立性的同时,高效地共享了信息和资源,极大提高了系统整体的灵活性和可扩展性,为后续油藏动态分析场景大模型的功能扩充提供了可操作空间。
2 面向油藏动态分析场景功能的模型微调实现与测试
2.1 分析建议模型的微调与测试
用于分析建议模型(模型A)的微调数据集总共包含110条微调数据,涉及单井动态分析77条、注采井组动态分析20条、区块动态分析13条。每条微调数据包含案例描述、需要解决的问题与解决方案3个部分,分别对应输入(inputs)、指令(instruction)、输出(outputs)。
通过调整模型A微调数据集中每个实例涉及的时期、阶段、层位信息得到330条测试数据,分别从是否相关、是否准确、是否完整、是否流畅4个维度对模型A的问答(QA)性能进行了评估。为减少偏差,表1 对比了3名油藏动态分析领域专家对模型回答效果的独立评判结果。结果显示,抛开主观因素,3位专家认为通过微调获得的分析建议模型能够很好地保证回答结果的完整性(准确率96.7%)和流畅性(准确率99.4%),而准确性(准确率88.3%)和相关性(准确率92.9%)虽有待提升,但在大多数问题的分析解答上仍然能够得到保证。究其原因,油藏动态分析涉及复杂的地质条件、多种生产方案及多变的动态响应,在一些案例中的时期、阶段和层位信息发生改变后,问题的整体分析思路可能无法再套用原有的模板。下一步,笔者将对存在上述情况的测试问题进行甄别,并对相关解决方案中原有的微调数据集进行拓展和补充,进一步调优模型A。
表1 分析建议模型的QA性能测试 |
| 评判 专家 | 评判样本 总数 | 相关维度 | 准确维度 | 完整维度 | 流畅维度 | ||||
|---|---|---|---|---|---|---|---|---|---|
| 准确样本数 | 准确率/% | 准确样本数 | 准确率/% | 准确样本数 | 准确率/% | 准确样本数 | 准确率/% | ||
| 专家1 | 330 | 307 | 93.0 | 295 | 89.4 | 326 | 99.0 | 330 | 100.0 |
| 专家2 | 330 | 315 | 95.5 | 297 | 90.0 | 324 | 98.0 | 328 | 99.4 |
| 专家3 | 330 | 298 | 90.3 | 282 | 85.5 | 310 | 93.9 | 326 | 98.8 |
| 综合 | 330 | 92.9 | 88.3 | 96.7 | 99.4 | ||||
2.2 特征提取模型的微调与测试
用于特征提取模型(模型D)的微调数据集总共包含256条微调数据,共有7个维度:井号(Well_id)、层号(Well_layer)、起始时间(Data_from)、终止时间(Data_to)、阶段(Period)、主要问题(Target),以及展示类型(Wanted_type)。微调后得到的模型D可将用户输入的信息转换为一个包含多维度数据信息的JSON字符串。
通过设计1 300条油藏动态分析领域综合性问题数据集,利用Dunn等[27]提出的命名实体识别准确率评价方法,从实体可识别率、数字变量实体识别准确率、语意识别准确率3个方面对模型命名实体识别的有效性和准确性进行综合评估(见表2 )。测试结果显示,“Target”语意识别准确率(91.5%)和“Wanted_type” 语意识别准确率(89.8%)有待进一步提升。由于模型在提取这两个维度的数据时,相关信息并不能直接从问题中截取,故准确率有所降低,下一步可通过实施更加精细的后处理规则适当降低错误率。
表2 命名实体识别模型的NER性能测试 |
| 命名实体 | 定义 | 总样本数 | 实体识别 | 数字变量实体识别 | 语意识别 | |||
|---|---|---|---|---|---|---|---|---|
| 正确样本数 | 可识别率/% | 正确样本数 | 准确率/% | 正确样本数 | 准确率/% | |||
| Well_id | 井号 | 1 300 | 1 275 | 98.1 | 1 247 | 96.5 | ||
| Well_layer | 层号 | 1 300 | 1 235 | 95.0 | 1 222 | 94.0 | ||
| Data_from | 起始时间 | 1 300 | 1 287 | 99.0 | 1 274 | 98.0 | ||
| Data_to | 终止时间 | 1 300 | 1 287 | 99.0 | 1 274 | 98.0 | ||
| Period | 阶段(如每年) | 1 300 | 1 261 | 97.0 | 1 274 | 98.0 | ||
| Target | 主要问题(如产油) | 1 300 | 1 209 | 93.0 | 1 189 | 91.5 | ||
| Wanted_type | 展示类型(如曲线图) | 1 300 | 1 235 | 95.0 | 1 168 | 89.8 | ||
2.3 数据检索模型的微调与测试
用于数据检索模型(模型B)的微调数据集微调后得到的模型能将自然语言查询问句转化为SQL查询语句。本文构建的油藏动态分析领域Text-to-SQL微调数据集包含油藏动态分析领域128条常见自然语言查询问题及其对应的SQL查询语句。
通过设计1 300条油藏动态分析领域常见自然语言查询问题数据集,按照Yu等[28]提出的不同SQL查询难度分级标准以及准确性测试方法,将数据集划分为简单、中等、复杂、极难4个等级,分别有700,500,80,20条SQL语句,对比测试了微调前后模型的Text-to-SQL性能(见表3 )。结果显示,与微调之前的石油工程行业大模型相比,微调后模型B匹配总体准确率提升了31.0个百分点,执行总体准确率达到95.2%。模型B的错误主要出现在复杂和极难等级的SQL语句,相关错误主要集中在较复杂、多层嵌套Select查询语句生成时输入的自然语言描述不准确而导致的歧义性。下一步可通过提示词限制Select查询语句语法结构的复杂度,避免Text-to-SQL语句本身的歧义性,进一步提升Text-to-SQL正确率。
表3 数据检索模型的Text-to-SQL性能测试 |
| 模型准确率标准 | 微调前匹配情况 | 微调后匹配情况 | 微调后执行情况 | ||||
|---|---|---|---|---|---|---|---|
| 分级 | 总样 本数 | 准确 样本数 | 准确率/ % | 准确 样本数 | 准确率/ % | 准确 样本数 | 准确率/ % |
| 简单 | 700 | 485 | 69.3 | 700 | 100.0 | 700 | 100.0 |
| 中等 | 500 | 337 | 67.4 | 498 | 99.6 | 462 | 92.4 |
| 复杂 | 80 | 46 | 57.5 | 70 | 87.5 | 53 | 66.3 |
| 极难 | 20 | 5 | 25.0 | 11 | 55.0 | 8 | 40.0 |
| 总体 准确率 | 67.3 | 98.3 | 95.2 | ||||
2.4 工具分类模型的微调与测试
用于工具分类模型(模型C)的微调数据集列举了油藏动态分析28种工具使用场景及其对应的类别标签(工具编号)。微调后得到的模型能将输入的自然语言描述转化为对应的工具编号。
通过设计与28种工具使用场景相关的1 300条测试问题,对比了3种不同的工具识别方法(见表4 )。结果显示,本文油藏动态分析场景大模型采用的“NER提取主旨信息(Target)+分类任务区分工具”方法准确率最高,达89.3%,而NER直接识别工具和分类任务直接区分工具的方法,准确率分别为35.9%和32.5%。这说明本文提出的通过命名实体识别技术提取关键实体信息后再进行分类的方法,可以使分类任务在少量训练样本上获得较好的整体微调效果,大幅提升了工具识别的准确性。
表4 3种不同的工具识别方法及其准确性评估 |
| 识别工具 | 准确样本数 | 准确率/% |
|---|---|---|
| NER直接识别工具 | 467 | 35.9 |
| 分类任务直接区分工具 | 423 | 32.5 |
| NER提取主旨信息(Target)+ 分类任务区分工具 | 1 161 | 89.3 |
3 场景大模型功能测试
以大庆油田PK3区块为例,选取油藏动态分析过程中的相关实际运用案例对本文场景大模型进行测试,主要为部分注采井组的辅助油藏动态分析,包括实时检索查询单井注采数据、梳理调取单井历史措施数据、调用软件绘制连井剖面、分析注采连通关系、分析注水受效层位。
PK3断块位于大庆长垣南部,含油面积55.3 km2,地质储量4 113×104 t,储层深度800~1 000 m,共划分26个层位。
3.1 实时检索查询单井注采数据、梳理调取单井历史措施数据
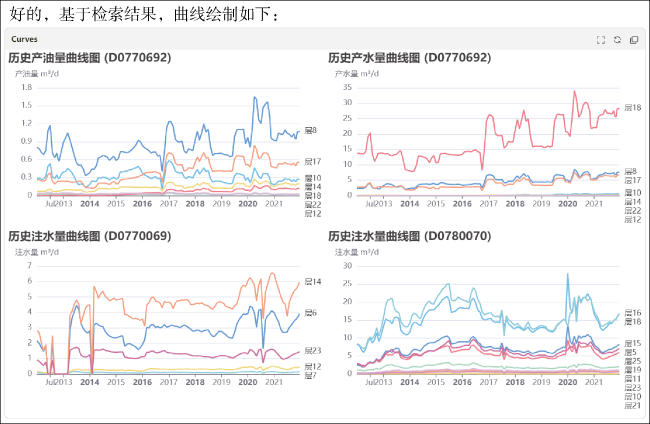
以PK3区块部分注采井组单元为例,油藏动态分析场景大模型能够通过文字语言表述直接访问数据库,调取相应注采数据,并显示出曲线图。选取的问题为:“查看D0770692井2012—2021年分层产油产水量数据,D0770069、D0780070井2012—2021年分层注水量数据,并显示曲线图”。油藏动态分析大模型能通过语言描述访问数据库,查询相关井的注采数据并生成曲线图(见图7 )。
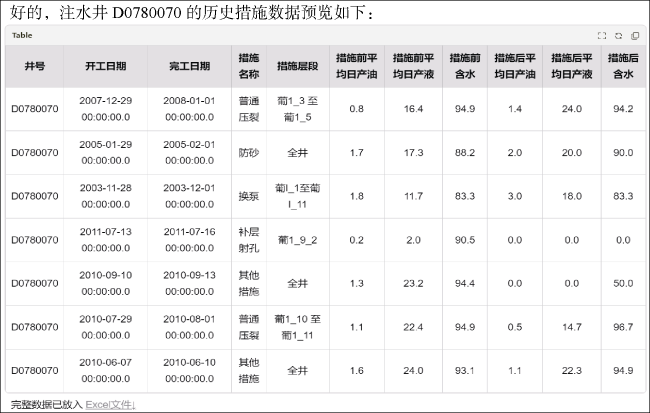
油藏动态分析场景大模型可以辅助查询梳理任意单井历史措施数据,方便油藏工程师随时调取和查看,本文选取的问题为:“梳理生产井D0780070的历史措施数据,并提供相关Excel文件”,结果如图8 所示。
3.2 调用软件绘制连井剖面、计算关键技术指标
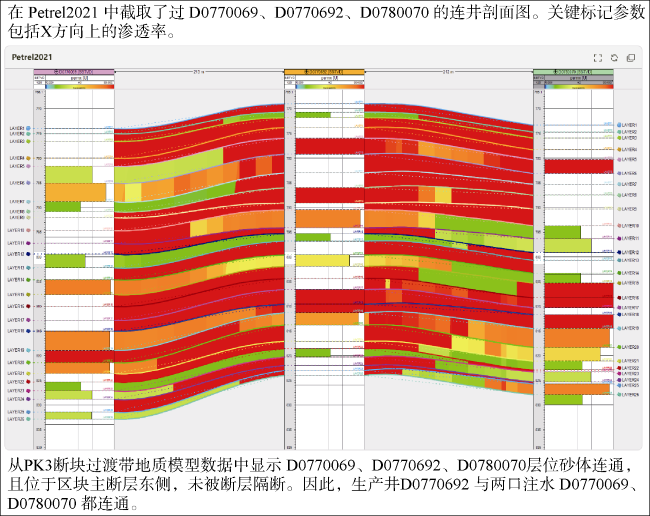
选取问题“调用Petrel2021软件绘制过D0770069、D0770692、D0780070这3口井的连井剖面,并标注X方向上的渗透率”测试模型工具调用能力。油藏动态分析大模型能够根据井的名称以及相关属性需求调用Petrel2021软件绘制出过井的连井剖面(见图9 )。同时微调后具备工具调用能力的油藏动态分析场景大模型能够从数据库中读取相关动态数据,并调用相关经验公式计算技术指标并返回结果,如选取问题:“计算PK3区块2020年的含水上升率”,大模型则根据数据库中的相关动态数据,调用公式计算出PK3区块2020年含水上升率为1.82%。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3.3 分析井组注采连通关系、单井注水受效层位
选取问题“分析D0770069、D0770692、D0780070井的注采连通关系”测试模型对井组注采连通关系的理解和分析能力,验证模型对复杂油气藏工程问题的处理效率。油藏动态分析场景大模型能够获取PK3区块地质模型数据中相关井位坐标、砂体连通情况以及断层位置等,并判断出相关井的注采连通关系,分析结果显示选取的3口井中生产井D0770692与注水井D0770069、D0780070都连通。从油藏工程专业角度分析,在生产动态曲线中,两口注入井提注或降注后,生产井的液量有明显响应,故判断生产井与两口注水井井间连通性较好,这与大模型分析结果一致。
选取问题“分析D0770692井的注水受效层位,并给出建议措施”测试大模型单井注水受效层位分析和建议能力。模型根据D0770692井历史分层产水量、分层渗透率数据,做出了相应的分析,并给出了判断和建议:①该井第18层产水量最高,第8层和第17层次之,第10,12,14,22层几乎不产水。②第18层注水受效程度最高,该层可能发生水淹,建议采取堵水措施。③第10,12,14,22层为低渗透层,几乎不受效,应尝试通过改变注水方式、压裂等技术手段来改善其储层的渗流能力。通过人工分析判断,该井第18层的平均产水量为20 m3/d,平均含水率达98.7%,该层确实已水淹,可见模型分析结果与实际生产现状具有较好的吻合度。
4 结论
本文采用增量预训练、指令微调和功能子系统耦合3个步骤构建了油藏动态分析场景大模型,提出了基于命名实体识别技术、工具调用技术、Text-to-SQL技术微调的功能子系统及其高效耦合方法,将人工智能大模型运用到油藏动态分析领域。最后以大庆油田PK3断块过渡带实际区块部分注采井组为例,测试验证了油藏动态分析场景大模型在辅助油藏工程师进行油藏动态分析方面具有的应用价值和潜力,为大模型在油藏动态分析中的运用提供了较好的技术支持。尽管本文的油藏动态分析场景大模型已初步实现了油藏动态分析助手的相关功能,实时检索查询单井注采数据、梳理调取单井历史措施数据、调用软件绘制连井剖面、分析注采连通关系、分析注水受效层位等,但其整体查询功能明显强于分析能力,距离真正落地运用于油藏动态分析工业领域仍需开展大量深入的研究工作。
专业领域大模型构建方面,本文所采用8.5 GB增量预训练的数据集体量,对于完全支撑一个专业领域大模型的构建需求还有差距。考虑油藏动态分析场景大模型分析能力仍需建立在专业领域大模型对油气开发专业领域案例提示词或上下文场景的深入阅读理解能力之上,未来可通过扩充高质量的油气工业语料库,进一步增强油藏动态分析场景大模型的分析理解能力,或是直接基于成熟的油气专业领域大模型开展场景大模型功能的研究。
油藏动态分析场景功能方面,未来可增加多样化的测试案例或模拟不同油藏特征的数据集,以提高该模型在各类油藏动态分析场景中的准确性和适应性,尤其是针对不同地质条件与油藏类型的分析。为适应油田数据的持续积累和油藏条件的变化,可尝试借鉴OpenAI于本年9月最新发布的o1-preview模型的相关工作机制,将慢思考模型应用到油藏动态分析当中,让模型可面向具体问题自主创建多步骤工作流程,并基于工作流程分步解决复杂问题,以使模型在复杂的推理任务方面拥有更加出色的表现。在系统维护方面,则可根据数据库结构变更与否建立半自动或自动更新机制,实现数据迭代更新。同时,考虑增加人机协同工作流程,允许油藏工程师对模型输出进行干预、修正或补充,并反馈至模型,将其有效融入模型的学习与优化过程中,实现人机协同的深度融合与互补。