

0 引言
油藏模拟历史拟合面临的挑战之一是再现孔隙介质中流体驱替的详细信息,进而识别每口井及生产井每个产层的见水时间。在这方面,Benlacheheb等[1]指出将更多监测数据用于历史拟合,可以获得与储集层物性垂向非均质性相关的更详细的信息。本文提出一种改进历史拟合方法,该方法将二元饱和度测井数据作为历史拟合质量的附加评价参数,以期建立一个更稳定、更可靠的油藏模型。本文方法将饱和度测井数据的原始格式转换为二元输出,可以简化拟合响应,从而能够基于更加复杂的方法(如机器学习等)来加速拟合过程。
1 理论基础
1.1 目标函数
模型的历史拟合质量通常用它的全局目标函数来表示。目标函数是一个数学函数,衡量模拟数据与实测数据之间的差别[2]。
在常规历史拟合方法中,首先,通过油藏描述收集所有油藏数据建立三维模型;然后,基于动态模拟数据和实测数据,利用模型预测生产历史;最后,利用目标函数将模型模拟数据与实测数据进行比较,评价模型的历史拟合质量。前人通过充分评估建立三维模型时可能采用的大量输入参数组合,并建立大量备选解决方案,将更全面的方法引入到地质建模过程中[3-4]。这些备选解决方案通常为代表性模型集合。根据不确定性分析得出的所有相关不确定性组合推导出一个更大的等机率集合,从中选定最终的代表性模型集合。代表性模型集合的选择主要依据其历史拟合质量。研究发现,将地质解释数据纳入历史拟合流程,模拟结果可提供最具代表性油藏模型的更多信息和静态油藏数据的不确定性信息[5-6]。
Mata-Lima[2]研究了评价模型性能和效率时目标函数的选择,分析发现考虑到历史拟合方法中常用参数的线性特征,均方根误差和平均差在历史拟合中应用最广泛。
1.2 常规历史拟合方法的局限
在常规历史拟合工作流程中,目标函数中通常使用油井产量(如产油量、产气量、产水量、总产液量)、压力和产量比(如含水率)等数据。众所周知,在任何建模过程中,模型能够描述的关键性能指标数量越多,模型的质量就越好。因此,使用有限的数据拟合油藏模型可能无法获得满意的代表性模型来预测未来的生产动态[7]。使用油井生产数据验证模型的主要挑战之一是如何准确识别合采井各产层饱和度的变化。测量近井地带含水饱和度变化的常用方法有两种,即饱和度测井和四维地震。饱和度测井数据通常在常规干扰监测中获得。四维地震技术有利于解释流体驱替[8-9],但这种技术应用中存在一些难点,需要更多算法和统计分析来预测流体饱和度。此外,四维地震数据通常不易获取,也会对经济预算产生影响。因此,本文引入饱和度测井数据作为附加评价参数。
1.3 分类指标
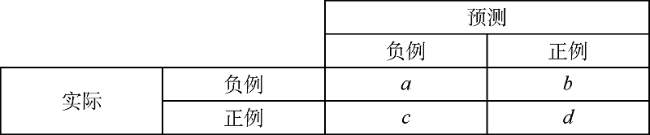
混淆矩阵衡量观察数据与预测数据之间的相关性,能够应用不同指标来关联数据。文献中给出了二元分类评估的各种指标组合,多数指标来自混淆矩阵。而Powers[12]指出,其中很多指标存在偏差和局限性,因此只能应用于特定的问题。本文涉及的二元分类指标包括精准率、召回率、F值、准确度、马修斯相关系数等。精准率指相关正确预测的比例,计算当预测为“是”时的正确频次,该指标没有考虑真负例的数量。召回率衡量正例分类的精度,计算当正确预测为“是”时预测为“是”的频次,是衡量预测为真正例的一项重要指标。F值为精准率与召回率的比值,对类分布的变化很敏感。准确度指正确预测与所有预测之间的比值,该指标对于非平衡数据不可靠,可能使分类器的预测结果过于乐观。
马修斯相关系数是Brian W. Matthews在1975年开展化学结构比较研究时引入的一种由混淆矩阵派生的分类指标[13]。马修斯相关系数表示实测分类和预测分类之间的相关性。与其他混淆矩阵指标相比,马修斯相关系数能够克服非平衡数据情况下产生的问题[14]。与其他混淆矩阵指标一样,马修斯相关系数也可以使用混淆矩阵的预测样本数据(TP、TN、FP和FN)进行计算。马修斯相关系数范围为-1~1,其中1表示预测理想或完全拟合,-1表示预测值和真实值完全不符,0表示几乎等于随机预测。马修斯相关系数是唯一一个只有当二元预测器能够正确预测大多数正例和负例数据样本时才产生高分的二元分类指标。根据以往统计研究和数据应用[14],多数情况下,马修斯相关系数可以提供比F值和准确度等其他非平衡二元指标更可靠的统计结果。
2 方法阐述
利用UNISIM半合成地质模型[15],结合基准测试流程,对本文提出的改进历史拟合方法与目标函数中仅使用产量的常规历史拟合方法进行对比。
2.1 本文方法的基准测试
利用改进的“大循环”工作流程(见图2 ),对本文提出的方法进行基准测试。这种基准测试流程不同于Kumar等[3]提出的原始工作流程,它只使用循环的第一次迭代来生成模型的集合,而不是进行迭代来提高模型集合的历史拟合质量。改进的工作流程分为两个阶段:第1阶段为基础模型生成阶段,也称预循环,生成基础模型或控制模型,表示真实油藏或实测数据;第2阶段为基准测试阶段,即“大循环”,根据基础模型建立模型的最终集合。在模型选择评估时,通过比较常规方法和本文方法,利用模型的最终集合对本文方法进行基准测试。
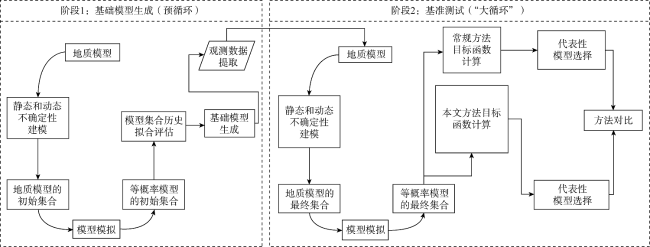
在第1阶段,使用所有可用数据建立基础油藏模型或实测数据模型。分析地质和动态输入,并引入工作流程中。定义和分析具有不确定性的变量及其取值范围,在不确定性分析基础上,利用蒙特卡洛算法,结合拉丁超立方采样方法,生成模型的初始集合。基础模型生成之后,确定关键生产井,以便对方法进行评估,在实际应用中这一步骤取决于单井饱和度测井数据。为了对本文方法进行基准测试,考虑模型中的所有生产井生产数据及各井每年一次的饱和度测井数据。
在第2阶段,为了生成模型的最终集合,使用与第1阶段相同的输入和变量,开展第2次不确定性分析。第1阶段和第2阶段不确定性分析的区别在于,第2阶段使用的实测数据对应第1阶段选择的基础模型的模拟数据。在生成模型的最终集合之后,使用常规方法和本文方法从集合中选择最佳的历史拟合模型。其中,常规方法采用基于生产井含水率的目标函数计算方法,本文方法采用二元饱和度测井数据和混淆矩阵指标来选择最佳历史拟合模型组。为了评估每组各个模型的历史拟合质量,使用不同的关键性能指标(如单井/单层产量),将所选模型与基础模型进行比较。
2.2 本文方法介绍
本文方法中基于饱和度测井数据的历史拟合质量评估是一个内插式模块,可作为任何历史拟合流程中的附加验证步骤。本文方法将套管井饱和度测井所得的储集层含水饱和度变化情况引入历史拟合流程,从而提高生产井周围地层含水饱和度变化的拟合精度。以下将对本文提出的基于饱和度测井数据的改进历史拟合方法的每个步骤进行详细介绍。
2.2.1 储集层饱和度测井曲线的二元解释
每口生产井的水线波及位置和推进情况是油藏生产过程中油藏特征认识和模拟的关键不确定因素。通过实施套管井饱和度测井,可以监测储集层中含水饱和度的变化。预测储集层饱和度变化的标准方法是对套管井测井数据进行解释分析。该过程需要使用包含岩石和流体性质的地层评价模型解释测井响应,还需要使用模拟井眼结构的其他参数,解释的结果是目的层含水饱和度的估计值。由于储集层评价模型中存在许多未知参数且数据可能存在噪声,这种解释结果存在很大的不确定性,给后续历史拟合带来挑战。
为了解决上述问题,需要建立一个表示水驱前缘突破的二元(是/否)波及标志。这是对正常流程的简化,通过这种简化,可以降低计算饱和度阈值时产生的不确定性,而这一阈值通常是在见水时确定。时移饱和度测井数据分析表明,对于任一深度段,含水饱和度会出现一次明显的变化,从初始的较低值变化到较高值,这与水驱前缘到达相对应。含水饱和度出现这种明显变化之后,后续变化很小。考虑到这一特征,可以简化现有的饱和度测井响应解释方法,即将中子测井响应出现变化的时间视为水驱前缘到达时间。受控于储集层性质和垂向非均质性,水驱前缘到达不同层段的时间不同,这些是历史拟合目标函数的关键补充实测参数。本文这种储集层“波及形式”表征方法所得结果与许多特殊岩心分析实验观察结果一致,即呈“活塞式”见水突破。岩心驱替实验和实际生产监测中通常也没有观察到含水饱和度的逐渐变化。
如图3 所示,通过模型模拟得到了不同时间点(2004年1月、2011年1月、2012年1月和2013年1月)含水饱和度的变化。然后对这些含水饱和度场景进行正演模拟,合成套管井饱和度中子测井响应。该过程模拟或再现了在实际油田开发中油藏监测可获得的实测数据。此外,图3 还显示了中子测井数据分析结果,生成了一系列二元解释数据,反映不同时间的储集层波及响应。通过这个过程,采用二元解释数据反映储集层中最显著的含水饱和度变化,不仅可以将含水饱和度变化从连续变量简化为二元变量,还可以降低含水饱和度变化的不确定性。本文提出的这种解释方法促进了不同来源测井解释数据(包括来自新加密裸眼井的解释结果)的应用,有助于确定油田开发几十年间水驱前缘到达时间,而无需考虑测井技术。

2.2.2 等概率模型饱和度测井曲线的生成
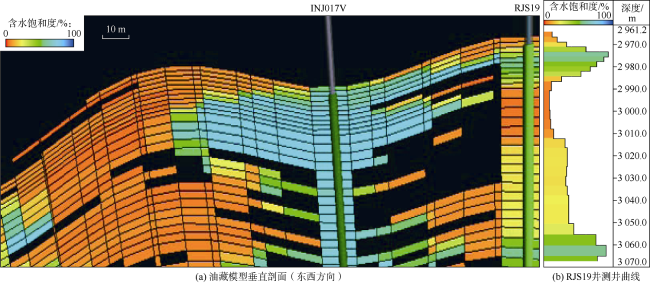
模型在记录每个网格单元流体性质变化的同时,还记录了井筒附近的含水饱和度和含油饱和度变化,因而可以估算模拟期间任何时间的合成饱和度测井曲线。合成饱和度测井可以捕捉沿井眼轨迹每个网格单元的流体饱和度。
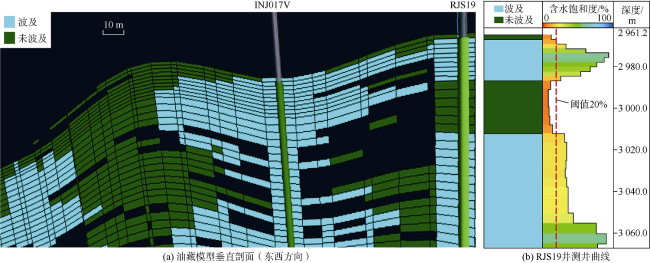
饱和度测井信息在生产井中至关重要,因为当含水饱和度增幅超过特定阈值时,可能与见水有关。图4 显示了模拟过程中某一时间点沿一对注采井井眼轨迹的含水饱和度二维垂直剖面,还显示了同一模拟时间点生产井的合成含水饱和度测井曲线。由图可见,注入井INJ017V的注入水在油藏顶部和底部形成了流向生产井RJS19的优势通道。在生产井合成含水饱和度测井中,这些优势水道被识别为高含水饱和度段。
根据所提出的工作流程,基于所有生产井的饱和度测井数据,生成合成饱和度测井曲线,为模型验证提供了一个新的评价参数。
2.2.3 饱和度测井数据的二元形式转换
为了将之前生成的合成饱和度测井数据转换为二元形式,需要使用含水饱和度阈值,该阈值为当水驱前缘到达生产井时近井单元的最低含水饱和度。二元饱和度测井数据分为波及类(水驱前缘已到达)和未波及类(水驱前缘未到达):当某个测井段的含水饱和度达到或超过阈值时,该测井段被判定为已波及;当某个测井段的含水饱和度未达到阈值时,该测井段被归为未波及。
根据已有的现场数据,本文采用经验或分析方法来估算含水饱和度阈值。
②经验法。如前所述,含水饱和度阈值是水到达井筒时生产井近井地带的最低含水饱和度。因此,如果某井开始产水时刻采集了饱和度测井数据,则测井记录的最大含水饱和度可作为阈值。该方法取决于井开始产水时是否开展饱和度测井。
2.2.4 基于混淆矩阵的实测测井数据和模型预测测井数据对比
由每个模型预测的二元饱和度测井曲线都可以直接与实测的二元饱和度测井曲线进行对比。对比过程中使用混淆矩阵分类指标,按深度对实测和模型预测测井曲线进行分段,可以针对整个测井深度建立一个混淆矩阵测井曲线。以模型1为例,预测得到的混淆矩阵测井曲线及其对应的混淆矩阵如图6 所示。
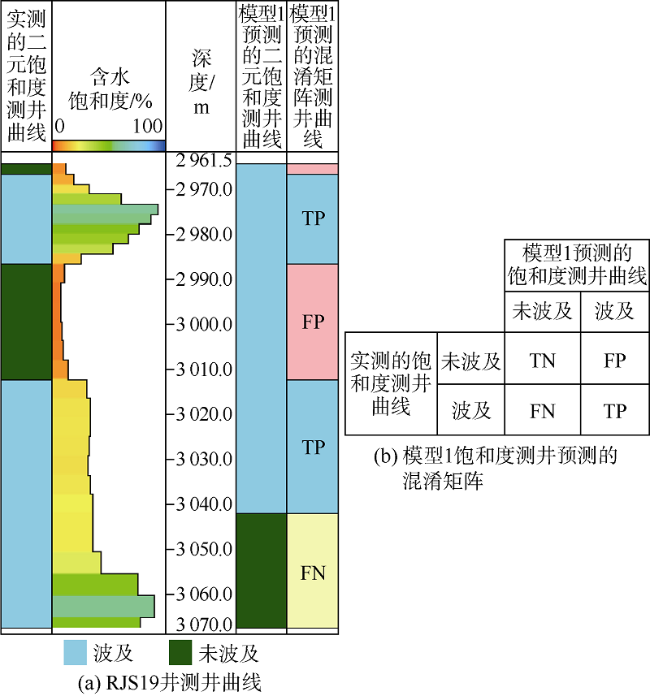
2.2.5 基于二元混淆矩阵派生指标的模型历史拟合质量评估
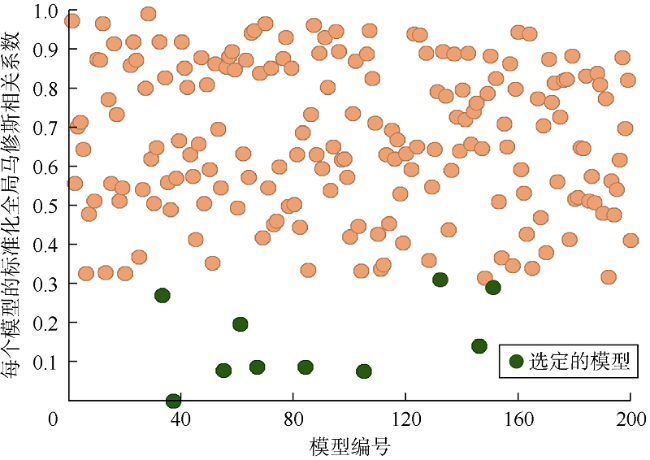
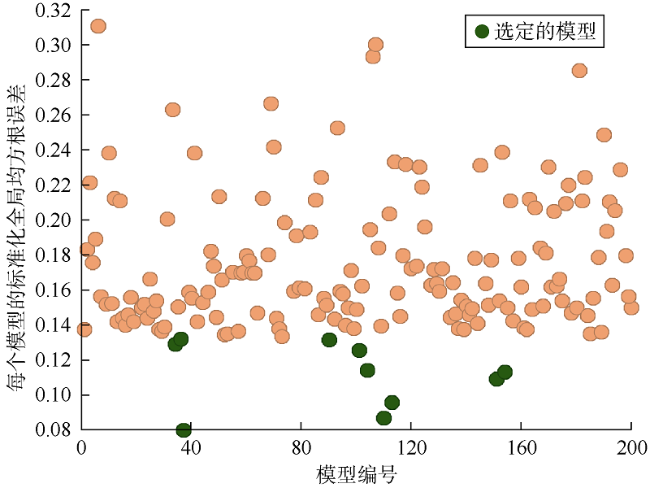
本文方法研究过程中对应用最为广泛的5个混淆矩阵指标进行了评估,以识别最适合判断二元饱和度测井吻合程度的指标。评估结果显示,马修斯相关系数是唯一一个可以用数值方法表示实测测井数据和模型预测测井数据之间吻合程度的指标。因此,首先计算集合中所有模型的马修斯相关系数。然后,根据马修斯相关系数计算结果,对所有模型进行排序,选出最优模型。
2.3 使用的地质模型
利用巴西坎皮纳斯州立大学(UNICAMP)开发的UNISIM半合成三维油藏模型对本文方法的可行性进行评价。UNISIM模型是基于巴西近海Campos盆地Namorado油田的公开数据,采用高分辨率三维网格建立的一个扇区半合成黑油模型。开发UNISIM模型的主要目的之一是采集到所有相关的储集层地质信息,以使UNISIM模型成为评价新方法的最佳基准模型之一。Namorado油田储集层位于背斜圈闭中,底部有活跃含水层。该油田分为3个主要驱替单元,对应3个沉积层序,层序间被不连续的泥灰岩层序分隔,垂向连通性较差。1条封闭断层将储集层分隔为两个储集单元,有两个油水界面。该油田采用注水开发,有生产井14口、注水井11口,生产7年。
对原始UNISIM模型进行了调整改进,以提高模型在非均质储集层和注水开发中的适用性。相关调整改进措施如下:①提高模型垂直分辨率。为了在模型中引入更多非均质性影响,以更好地表征储集层流体运动,在3个独立层中细分模型网格,所有层位的垂直单元分辨率提高2倍。②调整井眼轨迹。为了简化水驱前缘监测模型,将现有井眼轨迹由水平井变为直井。为了扩大模型的适用范围,并引入更全面的油藏开发策略,改变井眼轨迹和注入模式,如图7 所示。③孔隙度和砂地比测井校正。在提高垂向网格分辨率并将井眼轨迹改为直井后,原始孔隙度和砂地比测井数据不再适用。建立随机模型时,需要输入孔隙度和砂地比测井数据,因此利用直井数据结合神经网络算法重新生成缺失的测井数据。通过这一改进,可以提高地层分辨率,获得更准确的垂向砂地比。
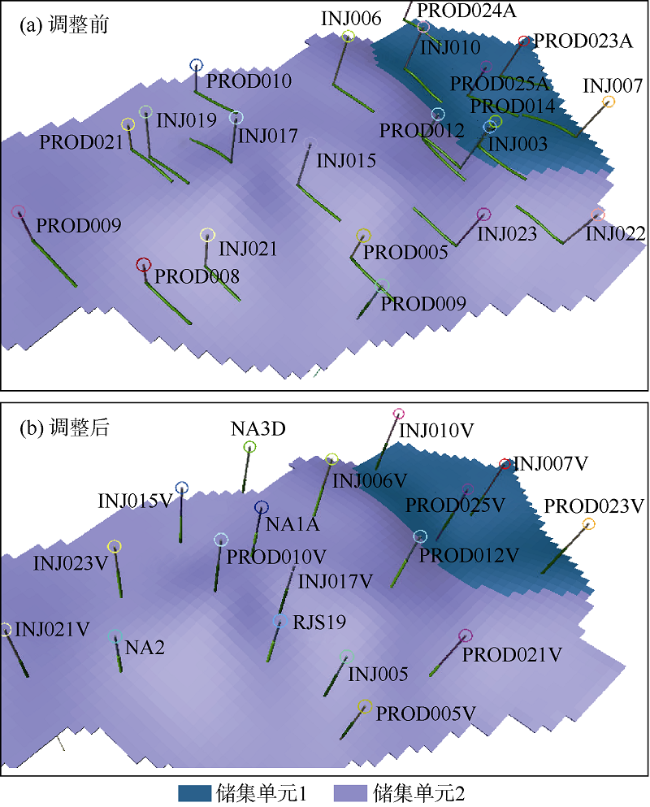
在改进所有模型后,考虑到Gaspar等[15]发现的UNISIM模型的不确定性,建立了不确定性矩阵。通过模型改进,并结合不确定性分析得到的不确定性范围,能够生成包括160个不同三维模型的初始模型集合,各模型的孔隙度和渗透率均存在区别。生成初始集合并选择基础模型(模型127)之后,在基准测试阶段生成了包含200个模型的最终模型集合。
3 方法应用与讨论
3.1 分类指标的评估
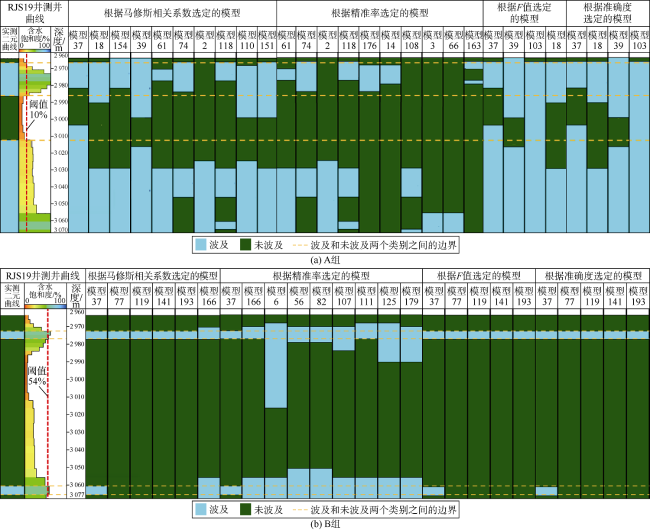
选择1口生产井和1个储集层饱和度测井日期,对分类指标进行评估。选择的生产井为RJS19,其垂向渗透率级差较大,选择的储集层饱和度测井日期为2013年8月8日,确保至少1个层的水驱前缘已经到达该井。此外,评估中同时使用经验法和分析法估算阈值(见图8 、图9 ),以减少阈值估算的不确定性。
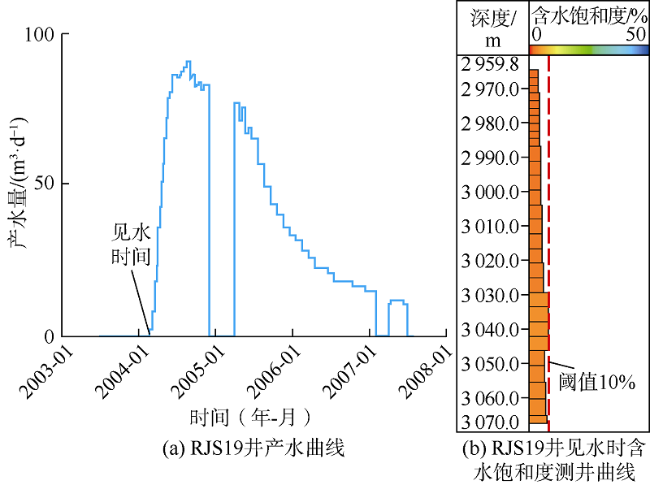
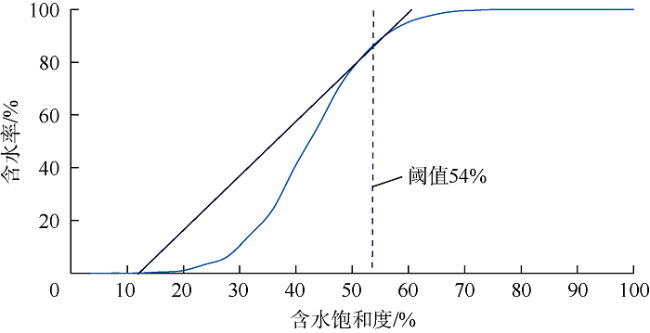
为了分析阈值不确定性对分类指标选择的影响,在最终集合的200个模型中,为RJS19井建立合成饱和度测井曲线,并分别根据经验法阈值和分析法阈值将其转换为二元饱和度测井曲线,前者为A组,后者为B组。
3.1.1 精准率
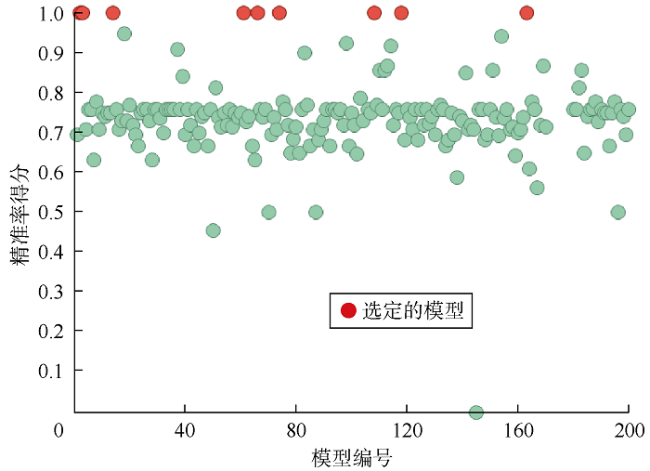
对于A组,对200个模型的精准率进行排序后,可以选出10个最佳模型,如图10 所示。而对于B组,无法选出10个最佳模型,因为有14个模型均达到了最大精准率,如图11 所示。这是因为,如Powers[12]指出及本文分析证实,在储集层饱和度测井二元背景下,未波及类型中精准率或真正率因受正类影响而出现偏差。
3.1.2 准确度、F值、召回率
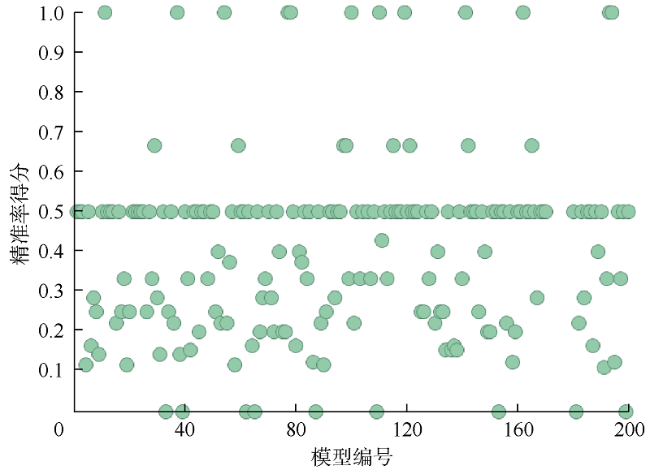
与使用精准率指标时的情况类似,使用准确度、F值或召回率指标时,也不是总能选出10个最佳模型,有时最多可以选出6个模型。对于这3个指标,集合中的大多数模型往往得出相同的指标计算值,因而无法对模型进行排序并选出一个代表性模型。
3.1.3 马修斯相关系数
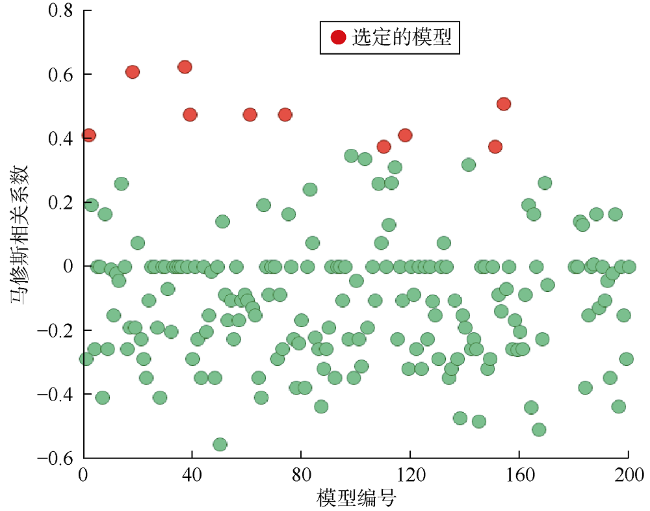
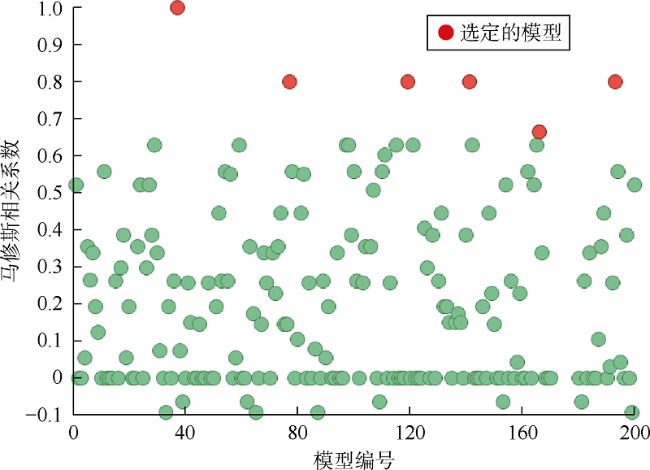
在A组中使用马修斯相关系数可以选出10个最佳模型,并且能够选出具有最佳拟合质量的模型(模型37),如图12 所示。在B组中,只有6个模型能够选择,如图13 所示。
3.1.4 分类指标评估结果
针对A组和B组,对比根据各分类指标选定的最佳模型的实测和模型预测二元测井曲线,如图14 所示。对于A组,根据精准率选择的所有模型都完全拟合未波及类别,但波及类别的拟合质量不佳。对于B组,根据精准率选择的所有模型都完全拟合波及类别,但未波及类别的拟合结果不佳。对于A组,根据准确度和F值选择的模型对波及和未波及类别的拟合都不准确。对于A组和B组,根据准确度、F值和马修斯相关系数,模型37均为整个模型集合中拟合质量最好的模型,但只有根据马修斯相关系数选择的最佳模型集合中包含了模型154(A组)和模型166(B组),而这两个模型的预测结果与实测二元饱和度测井曲线接近,拟合效果较好。与实测的二元饱和度测井曲线相比,马修斯相关系数指标在波及和未波及类别之间呈现出最平衡的结果,与所使用的阈值无关。评估结果表明,评价两个同等重要的类别时,马修斯相关系数是最佳的历史拟合质量评价指标。由于马修斯相关系数认为所有类别同等重要,减小了类别偏差。当选择过程中引入更多关键性能指标时,马修斯相关系数差异性还有助于提高模型选择的灵活性。
3.2 本文方法与常规历史拟合方法的对比
考虑整个生产历史期间所有生产井的生产数据和各井每年1次的饱和度测井数据,对本文方法与常规历史拟合方法进行对比。由于Welge法存在局限性,因此对比时只使用经验法计算阈值。常规历史拟合方法采用基于含水率的目标函数选择10个最佳模型,目标函数基于标准化均方根误差计算方法建立。本文方法使用马修斯相关系数选择最佳的10个模型。
采用所有生产井的数据,用常规方法和本文方法分别计算全局误差,即为各井的累计误差。为了便于比较,对全局误差进行归一化(0~1)。分别采用两种方法计算200个模型的全局误差,选择全局误差最小即拟合质量最好的10个模型,结果分别如图15 和图16 所示。两种方法均选择了模型37和模型151,模型37均排名第1,而模型151排名不同。
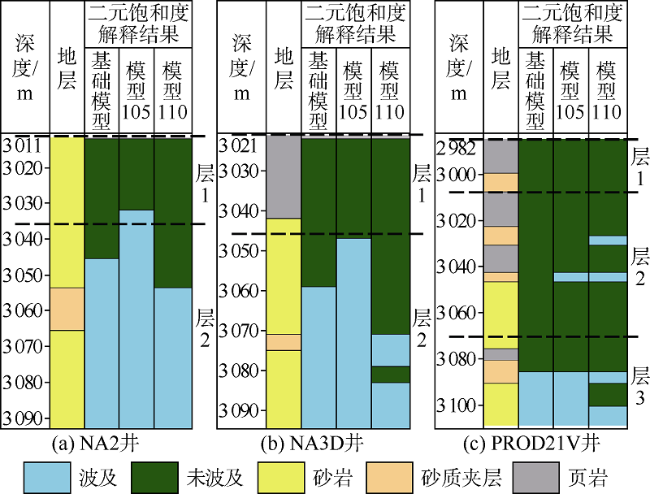
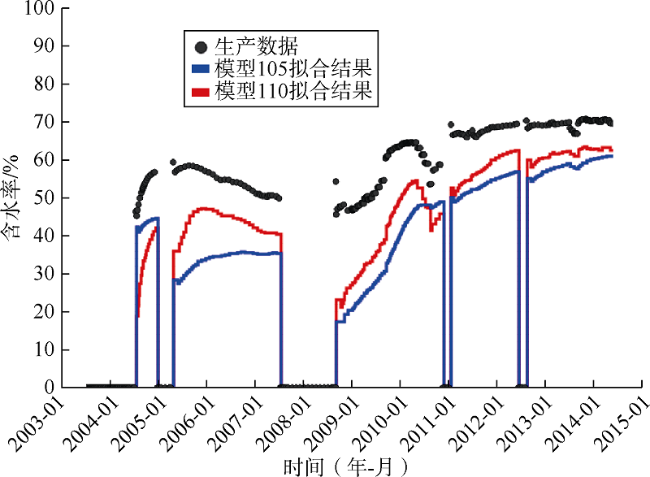
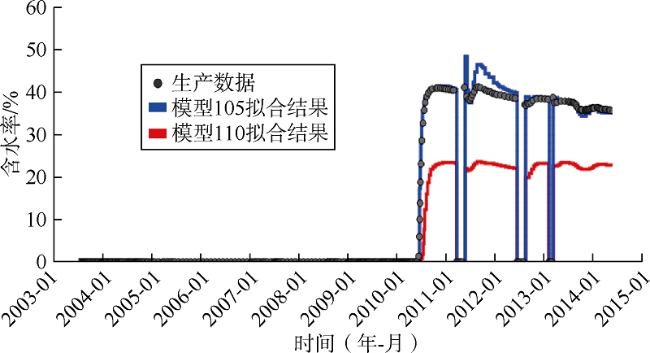
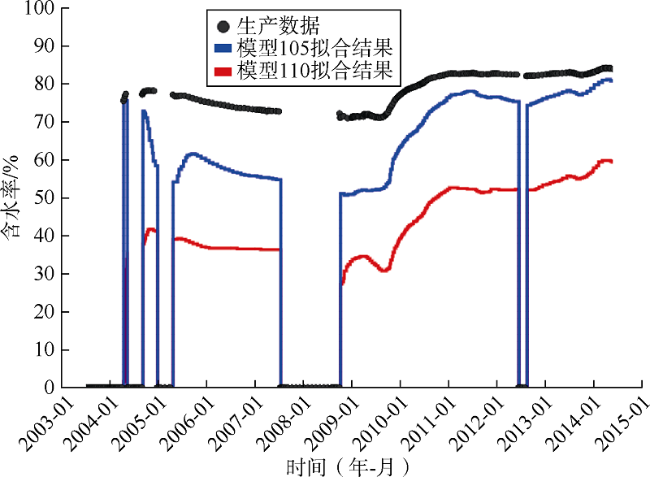
为了对比两种方法选出的最佳模型的历史拟合质量,对本文方法选出的排名第2的模型105和常规方法选出的排名第2的模型110进行分析,并与基础模型进行比较。考虑井位和地层纵向非均质程度的代表性,选择NA2井、NA3D井和PROD021V井作为3口典型井进行分析。3口井储集层纵向非均质性不同:NA2井和NA3D井的砂岩厚度大、物性好,被一个物性差的砂质夹层分隔;PROD021V井储集层垂向连通性较差,薄砂层被页岩层和砂质夹层分隔,储集层非均质性最强。3口井的完井地层剖面如图17 所示。通过与基础模型拟合结果的对比可以看出,采用本文方法选择的模型(模型105)对近井地带含水饱和度的历史拟合质量比常规方法更好。
对3口典型井的含水率进行了拟合,结果如图18 —图20 所示。可以看出,对于NA2井,两个模型拟合质量都较好,常规方法选出的模型拟合质量略优于本文方法选出的模型。而对于NA3D井和PROD021V井,本文方法选出的模型的拟合质量明显优于常规方法选出的模型。总体上,本文方法选出的模型对生产井含水率的拟合质量优于常规方法选出的模型。
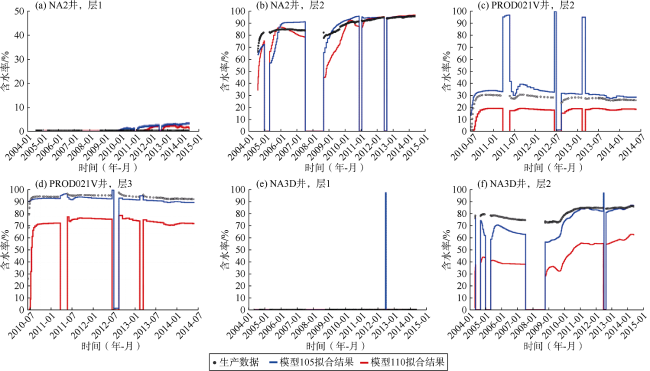
对典型井不同层位的含水率进行了拟合,结果如图21 所示。可以看出,总体上本文方法选出的模型的拟合质量仍然优于常规方法选出的模型。常规方法的分层含水率拟合效果差,无法识别不同层位水驱前缘到达时间。根据模拟目标的不同,更好地表征实际层间和层内水驱可能为决策过程提供重要信息。例如,如果模拟的目的是评估增加或封堵射孔孔眼对降低产水量的影响,那么1个能够详细表征不同层位水驱的模型至关重要。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4 结论
采用由混淆矩阵推导的统计分析指标(如马修斯相关系数),可以衡量油藏模型的历史拟合质量。马修斯相关系数指标认为所有类别同等重要,可以减小类别偏差,能够选择更多类别平衡的模型集合。
使用二元储集层饱和度测井数据作为拟合参数,可以选择分层/分砂体历史拟合质量更好的模型。在选择不同历史拟合方法时,储集层非均质性具有重要影响,在强非均质水驱油藏中,以储集层饱和度测井数据作为拟合参数,拟合效果最好。
当使用储集层饱和度测井数据作为拟合参数时,历史拟合质量与每口井开展的储集层饱和度测井作业数量高度相关。当无法获得可用数据时,本文方法有效性变差。对于所选模型,使用储集层饱和度测井数据进行历史拟合的质量取决于可用的储集层饱和度测井样本数量和采样日期。若在生产过程中采集到时间点分布较好的储集层饱和度测井数据集,将有助于选出能更好地模拟整个生产历史的模型。
与常规历史拟合方法相比,本文方法对近井地带含水饱和度、生产井及其不同层位含水率的拟合质量更好。
致谢
感谢朴茨茅斯大学和伦敦南岸大学提供的技术支持和资源。感谢中海油国际有限公司以及所有为本研究贡献了知识和经验的同行和同事们,特别感谢Azra Kovac、Jeremy Rhodes、Maria Trujillo、Murdo Paterson、Clive Sirju和Ben Fletcher提供的指导和帮助。