

0 引言
油井产量是油田开发的首要指标,预测产量变化是油田开发动态分析的关键环节。单井产量变化受储集层性质、措施等诸多因素影响,合理考虑各因素影响规律、准确把握产量变化特点是实现单井产量准确预测的关键。相较递减曲线、油藏数值模拟等传统产量预测方法,机器学习方法具有强大的非线性拟合能力和高效率,在产量预测方面具有极大的应用潜力。
对于多影响因素、长时间跨度、多序列并行的单井产量预测,前人仅使用少数几个特征构建模型。若要进一步提高单井产量预测精度,需全面考虑动静态影响因素,构建多特征的产量预测模型。当特征数据增多时,RNN难以兼具对高维空间信息和时序信息的提取,模型预测精度受限,故有必要采用一种新算法实现对单井产量的准确预测。时域卷积神经网络(TCN)是一种可以处理时序信息的卷积神经网络(CNN),CNN的基础结构使它在拟合单井产量时序关联的同时可以从诸多特征中提取出关键特征,实现精准的单井产量预测。
基于此,本文提出使用TCN构建模型进行水驱油藏单井产量预测。首先综合考虑储集层、注水、措施等动静态因素构建数据集,针对数据特点进行数据空缺填充和数据异常校正。然后针对油井各阶段生产规律复杂、难以捕捉的难点,依据油井含水率划分生产阶段分别建模,使用麻雀搜索算法(SSA)进行模型超参数寻优,最终将阶段模型集成为全生命周期模型实现全井预测。
1 算法基本原理
1.1 时域卷积神经网络
TCN是以膨胀的因果卷积层为基础结构、以时间序列为输入的卷积神经网络模型[11]。因果卷积指左填充的一维卷积神经网络,它赋予了TCN时间约束特性,使其适应于时序问题。膨胀卷积指依一定规律增加卷积层步幅后的卷积层,它可以显著提高卷积神经网络感受野,使TCN可以抓取更长的时序依赖关系,解决了传统卷积神经网络对时序的建模长度受限于卷积核大小的问题。对于长输入的任务,在TCN中引入残差连接可显著降低覆盖全部输入所需的卷积层层数或卷积核大小。为防止因网络层数过多而导致的梯度消失/爆炸问题,可在每一层卷积网络后添加权重归一化。相较LSTM等循环神经网络,TCN的卷积神经网络结构使其具有可并行、收敛快、跨时域的特点。
1.2 麻雀搜索算法
使用适当的优化算法可以快速筛选出神经网络模型的最佳超参数,极大地提高模型构建效率。
SSA是一种模拟自然规律的群体优化方法[12],从麻雀的群体智慧、觅食行为和反捕食行为出发,将潜在的超参数组合设定为麻雀的位置,不同位置的麻雀具有不同的适应度(即该超参数组合下模型的预测精度)。依照一定规律将麻雀分为生产者、觅食者和发现者3类,3类麻雀会在每一次迭代中改变位置、交换身份。给定最大迭代次数、生产者数量、发现者数量、麻雀总数和安全阈值,经过有限次位置迭代,适应度最高的麻雀的位置将是最佳的超参数组合。
2 数据收集与处理
2.1 油田数据采集
大庆长垣油田某水驱区块具有60多年的开发历史,为典型中高渗砂岩油藏,目前该区块油井已普遍进入高含水及特高含水阶段,部分井含水率超过98%。自1960年采用基础井网投入开发以来,该区块经历了井网调整、全面转抽、三次加密、“二三结合”、压裂酸化等多种增产措施,厚油层底部水洗程度高,注入水低效循环。由于开发井网密集、注采关系复杂、增产措施频繁,常规动态分析方法误差较大,数值模拟应用困难、收敛较差。
选取油藏基础数据、区块基础数据、520口油水井的单井储集层数据和单井基础数据、426口油井的月度生产数据、94口水井的月度注水数据、单井措施数据构建数据集,其中油井月度生产数据平均时间跨度406个月,共计173 187条。
2.2 数据处理
2.2.1 数据填充与降维
空缺填充和异常样本校正是构建高质量数据集的关键环节,数据填补、校正质量与模型预测精度直接相关。针对数据集中静压、流压、动液面3项特征部分数据缺失的问题,提出基于随机森林模型的空缺填充方法。首先计算预填充特征与其他特征的斯皮尔曼相关性系数,筛选相关性系数大于0.2或小于-0.2的特征;其次建立影响特征与预填充特征的随机森林模型,使用已有数据进行模型训练;最后输入缺失数据的主控因素进行模型预测,模型预测值即为填充值。
针对泵径、泵深和油嘴3项特征部分数据存在异常零值的情况,采取向前/向后看齐的校正策略,即对于异常数据,在该井井史范围内从当前时间步同时向前向后寻找非零正常数据,使用先找到的非零正常数据替代该时间步的异常零值。对于某项特征数据全缺失的井,使用与该井距离最近井的特征平均值填充。若有多个特征全缺失的井,酌情取舍。
为得到更准确的模型预测结果,需适时进行特征压缩,以提高特征质量、控制特征数量。数据集中静态特征较多,包括类别特征和数值特征,其中类别特征经独热编码处理后表现为高维的稀疏0-1矩阵,为防止类别特征淹没在密集变化的数值特征中,分别以95%置信度使用主成分分析法(PCA)对类别特征和数值特征进行降维,最终形成33维的静态压缩特征。
2.2.2 数据整合
本文动态数据主要包括油井生产序列、水井注水序列、小层措施序列3类,为符合模型输入数据格式,应将描述注水和措施的序列整合至油井生产序列中。
为整合水井注水序列至油井生产序列,提出注水井影响半径法,定义油井当月受注水井影响程度It,i并将其作为特征增加到数据集中。注水井影响半径由It,i与产油量之间的斯皮尔曼相关性系数确定,本文选取相关性系数最高的1 000 m作为影响半径。以水井为圆心、以影响半径为半径划出影响范围,在影响范围内的油井即为受注井。
$I_{t, i}=\sum_{j=1}^{n_{\mathrm{w}, i}} \frac{W_{t, j}}{D_{i, j}}$
$D_{i, j}=\sqrt{\left(x_{\mathrm{o}, i}-x_{\mathrm{w}, j}\right)^{2}+\left(y_{\mathrm{o}, i}-y_{\mathrm{w}, j}\right)^{2}}$
对小层措施数据进行合并、数值化处理。在数据集中添加压裂、堵水等6项类别特征和措施层厚度1项数值特征。若油井的某小层进行了某类措施作业,则该月对应类别特征记录为1,措施层厚度则记录为作业小层厚度的和。
整合后最终数据集特征包括注水特征、措施特征、油井静态特征和生产动态特征4部分。此外,对输入序列进行标准化处理、对产量序列进行平滑处理,以增加模型平稳度、降低拟合难度。
2.3 特征参数分析
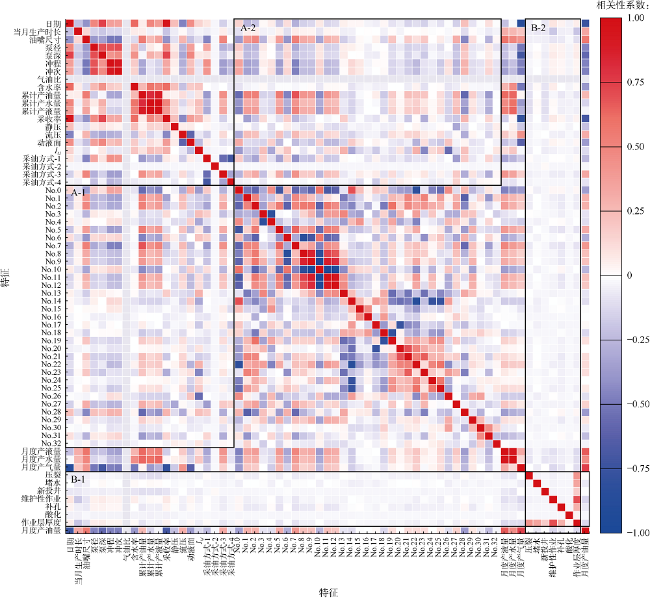
在本文数据集的70余项特征中,部分描述油藏构造和区块参数的特征对单井产量预测作用不大,故去除油藏类型、沉积相等10余项特征,经特征工程处理后形成65项最终特征。计算65项特征之间的斯皮尔曼相关性系数并绘制热力图,以颜色的深浅表示特征相关性的强弱,红色为正相关、蓝色为负相关(见图1 )。编号No.0—No.32的特征为降维处理后表示单井地质、工程特点的抽象特征,由于其在时间上不变,整体呈弱相关性,如A-1、A-2区域所示。B-1、B-2区域特征为压裂、堵水、维护、补孔、酸化等措施特征,其在数值上表现为稀疏的0-1矩阵,故相比数值特征呈现出极弱的相关性。对于预测目标月度产油量,与其相关性最强的特征依次为月度产气量、日期、采收率、月度产液量、泵深、油嘴尺寸、含水率、泵径、No.7、月度产水量等。
2.4 油井生产历程划分
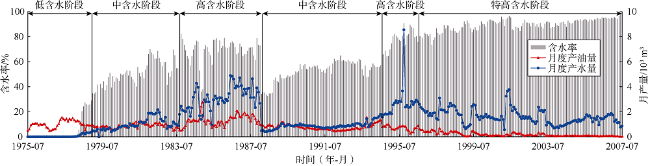
在油井长达60年的生产历史中,产量变化存在显著的阶段性,为准确把握不同生产阶段油井产量的变化特点,需要划分阶段、分别建模。本文依据油井含水率变化规律编写算法自动划分单井生产历程,fw< 30%,30%≤fw<60%,60%≤fw≤80%,fw>80%分别对应低、中、高、特高含水阶段(见图2 )。由于含水率数据存在不连续或突变,而生产阶段相对连续,在对训练集进行阶段划分前应对含水率序列进行阶梯化处理。建立4个阶段预测模型然后集成,预测时给定输入各月生产阶段判断权重,确定待预测月所处生产阶段,然后由相应阶段模型进行预测,最终的全生命周期预测结果由各阶段预测结果拼接得到。
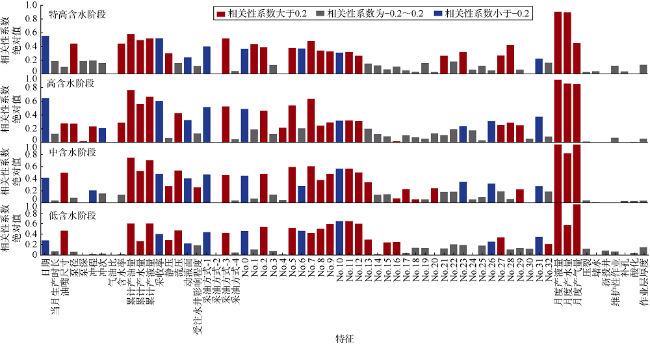
不同生产阶段月度产油量主控因素也会有差异,需要计算4个生产阶段月产油量与其他特征的相关性系数,筛取相关性系数大于0.2或小于-0.2的特征分别构建输入数据集,各阶段模型最终输入特征如图3 所示。
2.5 时间滑窗与数据集划分
以井为单元划分数据集:341口油井用于模型训练,43口油井构成验证集用于进行超参数的寻优,42口油井构成测试集用于模型测试。采用时间滑窗方法生成输入数据,指定输入步长和输出步长,分别构建适应于各个模型的输入和标签。
3 模型结构及评价
3.1 模型结构设计
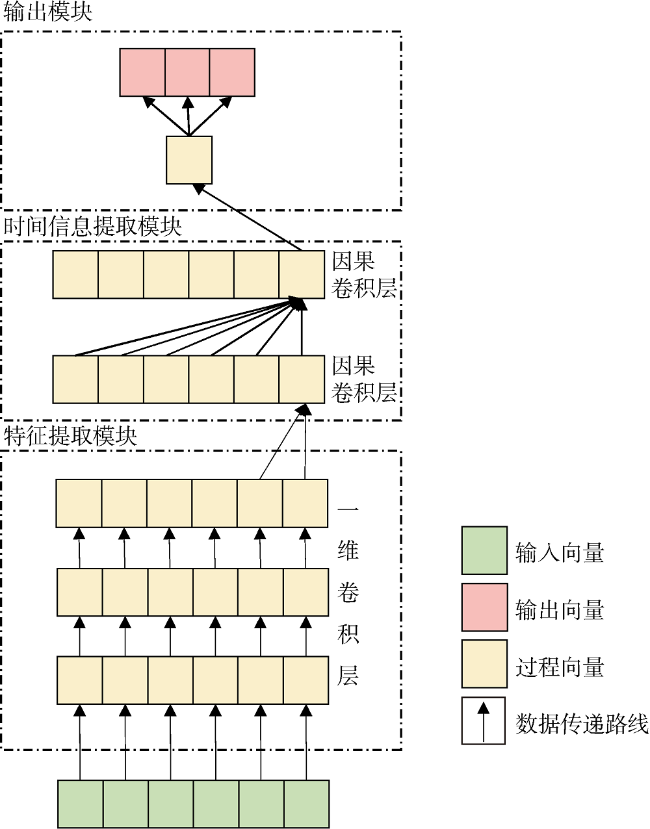
针对单井产量预测特征数量多、时间步长短、数据体量小等特点,对TCN模型做3个方面的改进:①在时间卷积层前堆叠卷积核大小为1的一维卷积层,提取特征;②不使用膨胀卷积和残差连接,设置因果卷积层卷积核大小为输入时间步长,步幅为1;③使用因果卷积层输出中最后一个时间步的值进行最终预测。改进后的TCN模型结构见图4 。
3.2 麻雀优化算法参数设计
使用SSA进行模型超参数寻优,最大迭代次数为50、生产者数量为20、发现者数量为20、安全阈值为0.8,麻雀总数为100。以12个月输入步长预测模型为例,TCN模型各层参数见表1 。
表1 改进的TCN模型超参数SSA寻优结果 |
| 网络层 | 滤波器数量 | 卷积核大小 | 膨胀率 | 作用 |
|---|---|---|---|---|
| 第1层 | 46 | 1 | 1 | 特征提取 |
| 第2层 | 25 | 1 | 1 | 特征提取 |
| 第3层 | 10 | 1 | 1 | 特征提取 |
| 第4层 | 46 | 2 | 1 | 时间信息融合 |
| 第5层 | 125 | 12* | 1 | 时间信息融合 |
注:*模型固定超参数,此处选择输入时间步长 |
3.3 对比模型设计
为全面评价本文改进TCN模型在产量序列预测中的适应性,基于当前时序预测领域5种代表性方法,构建11种产量预测模型进行对比,包括:①CNN和LSTM[13]的组合模型CNN-LSTM;②LSTM模型;③基于编码解码机结构[14]并在时间维度添加Luong注意力机制[15]的LSTM模型,即Attention-LSTM(T);④添加Temporal Pattern Attention[16]机制实现对特征注意力的LSTM模型,即Attention-LSTM(F);⑤结合Luong注意力机制和Temporal Pattern Attention机制同时实现对时间和特征注意力的LSTM模型,即Attention-LSTM(T&F);⑥在特征维度添加注意力[17⇓-19]的自注意力机制模型Self Attention(F);⑦在时间维度添加注意力的自注意力机制模型Self Attention(T);⑧同时在时间维度和特征维度添加注意力的自注意力机制模型Self Attention(T&F);⑨LSTM和特征维度自注意力机制的结合模型Self Attention-LSTM(F);⑩LSTM和时间维度自注意力机制的结合模型Self Attention- LSTM(T);⑪LSTM和时间、特征维度自注意力机制的结合模型Self Attention-LSTM(T&F)。对比模型超参数同样由SSA寻优得到。
3.4 模型训练设计
基于编码解码机结构的模型使用Teacher Forcing策略进行训练。为实现最佳的训练效果,文中模型优化器选择Adagrad算法,初始学习率均设为0.05,并使用ReduceLROnPlateau回调函数实现对学习率的控制。为防止过拟合,在模型中应用层正则化,并使用EarlyStop回调函数控制训练进程。为减少模型训练随机性带来的不确定性,模型准确性评价结果来自相同参数设置下3次实验后的平均值。
3.5 模型评价
模型预测的准确性采用平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、复相关系数(R2)和均方根误差(RMSE)来评价,如(3)—(6)式所示。
$M A E=\frac{1}{N} \sum_{k=1}^{N}\left|q_{k}-\hat{q}_{k}\right|$
$M A P E=\frac{1}{N} \sum_{k=1}^{N} \frac{\left|q_{k}-\hat{q}_{k}\right|}{q_{k}} \times 100 \%$
$R^{2}=\frac{\sum_{k=1}^{N}\left(q_{k}-\bar{q}\right)^{2}-\sum_{k=1}^{N}\left(q_{k}-\hat{q}_{k}\right)^{2}}{\sum_{k=1}^{N}\left(q_{k}-\bar{q}\right)^{2}}$
$R M S E=\sqrt{\frac{\sum_{k=1}^{N}\left(q_{k}-\hat{q}_{k}\right)^{2}}{N}}$
4 应用与讨论
4.1 算法对比
应用上述12种模型预测42口采油井的产量,以输入步长为12个月、输出步长为3个月为例,统计了第13个月预测值的平均绝对误差(见表2 ),其中集成模型表示由4个阶段模型集成的全生命周期模型,单一模型为使用全部数据笼统训练的全生命周期模型。由表2 可知,改进的TCN模型预测精度最高,集成模型的平均绝对误差为17.66 m3,较单一全生命周期模型预测误差低3.05 m3。
表2 不同模型第13个月预测值的平均绝对误差对比表 |
| 模型 | 阶段模型平均绝对误差/m3 | 全生命周期模型平均绝对误差/m3 | |||||
|---|---|---|---|---|---|---|---|
| 低含水阶段 | 中含水阶段 | 高含水阶段 | 特高含水阶段 | 集成模型 | 单一模型 | ||
| 本文改进的TCN | 23.22 | 17.93 | 13.15 | 19.53 | 17.66 | 20.71 | |
| 对 比 模 型 | CNN-LSTM | 30.86 | 18.89 | 19.84 | 21.44 | 21.39 | 21.60 |
| LSTM | 37.55 | 22.71 | 16.98 | 22.40 | 22.35 | 22.55 | |
| Attention-LSTM(T) | 65.26 | 31.31 | 38.95 | 28.13 | 35.72 | 30.20 | |
| Attention-LSTM(F) | 53.80 | 25.58 | 32.27 | 25.27 | 30.28 | 30.20 | |
| Attention-LSTM(T&F) | 75.77 | 38.00 | 42.78 | 31.95 | 40.79 | 40.71 | |
| Self Attention(F) | 65.26 | 36.09 | 25.58 | 40.55 | 37.63 | 34.02 | |
| Self Attention(T) | 131.19 | 61.89 | 33.22 | 49.15 | 55.12 | 33.06 | |
| Self Attention(T&F) | 139.79 | 92.46 | 30.35 | 44.38 | 59.32 | 34.98 | |
| Self Attention-LSTM(F) | 79.60 | 38.95 | 27.49 | 31.00 | 36.39 | 25.42 | |
| Self Attention-LSTM(T) | 92.97 | 46.60 | 93.42 | 33.86 | 54.18 | 26.38 | |
| Self Attention-LSTM(T&F) | 110.17 | 54.24 | 121.13 | 31.00 | 60.60 | 28.46 | |
注:T—在时间维度添加注意力机制;F—在特征维度添加注意力机制 |
注意力机制在机器翻译、语音识别等多个时间序列预测任务中都被证实对模型预测能力具有显著的提升作用[20⇓⇓-23],本文研究了9种添加注意力机制的模型,但均未取得较高的预测精度(见表2 ),这表明注意力机制对生产数据预测任务的适应性不强。分析认为:①对于本文产量预测任务而言,决定下一时刻产量的不是先前某几个时刻的产量及其影响因素,而是一段时间内生产动态的整体变化趋势。注意力机制的引入令模型赋予个别时间步较大的权重,干扰了产量及其影响因素在一段时间内的整体变化趋势,导致模型预测精度降低。②LSTM模型已有足够能力分析12个月生产动态数据,引入的注意力机制无法发挥出处理长时间序列数据的优势,反而加大了模型的训练难度,最终降低了模型预测精度。③在特征维度上引入注意力机制会增加模型结构的复杂性和待训练参数量,随着模型拟合能力的增加,数据集中的弱噪声会被模型误学习而出现过拟合现象,降低模型的预测精度。
对比4个不同生产阶段模型发现,所有算法下低含水阶段模型的预测精度均为最低,原因是低含水阶段在油井生产历程中只占据很小的一部分,样本数目不足,模型训练不充分。
4.2 数据填充校正方法对比
随机筛选8口动态数据缺失较多的井进行数据填充校正效果对比。表3 列出了TCN模型分别采用本文方法、使用平均值填充且不进行异常数据校正的方法、使用插值填充法填充并进行异常值校正的方法、使用平均值填充且进行异常数据校正的方法处理输入样本预测结果。4个评价指标均证实本文数据填充校正处理的有效性,输入样本平均预测误差最小、精确率最高。
表3 TCN模型采用不同填充校正方法处理的输入样本预测结果对比表 |
| 数据处理方法 | MAE/m3 | MAPE/% | R2 | RMSE/m3 |
|---|---|---|---|---|
| 本文方法 | 23.83 | 5.16 | 0.99 | 63.57 |
| 均值无校正 | 26.13 | 5.42 | 0.98 | 68.10 |
| 均值有校正 | 25.72 | 5.32 | 0.98 | 69.25 |
| 插值有校正 | 24.35 | 5.29 | 0.99 | 64.02 |
注:以12个月的生产数据为输入,预测未来3个月的产量;表中数据为第13个月产油量预测值的误差评价数据 |
4.3 输入步长对比
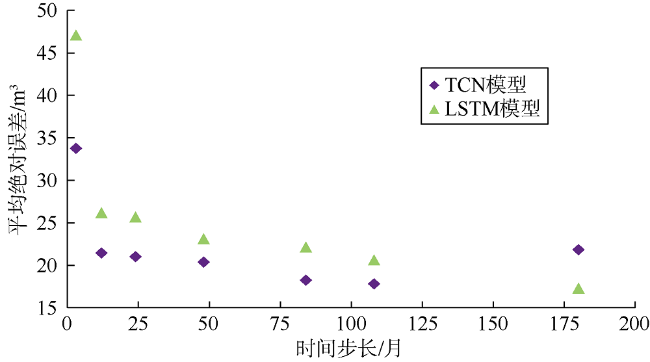
以单一全生命周期模型为例,分别用TCN模型和LSTM模型验证不同输入步长对模型预测精度的影响(见图5 ),在短输入步长时TCN模型预测效果较LSTM模型更好,在长输入步长时LSTM模型预测效果更好。由于本文对油井生产历程进行了划分,井的平均连续时间跨度由406个月降至103个月,若使用较长的输入步长,样本的数量会非常少,可预测的阶段几乎都集中于特高含水阶段,应用受限。图5 显示TCN模型在12~50个月的时间步长范围内预测精度相近,在保证模型预测精度的前提下,选择12个月的时间步长以实现样本数量的最大化。
4.4 模型结构分析
4.4.1 堆叠一维卷积核层进行特征提取的必要性
表4 添加和不添加特征提取层的TCN模型3个预测值的定量评价结果 |
| 方法 | MAE/m3 | MAPE/% | R2 | RMSE/m3 |
|---|---|---|---|---|
| 不添加特征提取层(13) | 26.83 | 5.46 | 0.99 | 60.12 |
| 不添加特征提取层(14) | 39.67 | 6.98 | 0.97 | 86.58 |
| 不添加特征提取层(15) | 52.77 | 11.23 | 0.95 | 112.69 |
| 添加特征提取层(13) | 20.71 | 4.96 | 0.99 | 53.57 |
| 添加特征提取层(14) | 35.80 | 6.31 | 0.97 | 84.31 |
| 添加特征提取层(15) | 49.94 | 10.05 | 0.95 | 111.07 |
注:以12个月的生产数据为输入,预测未来3个月的产量,(13)、(14)、(15)分别为第13个月、第14个月、第15个月的预测月产量 |
4.4.2 因果卷积层输出的选择
因果卷积层的输出是长度与输入时间步长相同的序列,使用全部输出做最后的预测还是使用有限个步长的输出作为下一层的输入对模型预测精度有较大影响。本文分别对比了使用全输出、最后1个月的输出、最后2个月的输出、后6个月的输出、后10个月的输出5种情况下的预测结果。结果显示,使用全输出反而会降低模型预测精度(见表5 )。因为最后一个时间步的输出已经涵盖了所有前序时间步的信息,足以完成预测。
表5 因果卷积层不同输出步长对模型预测结果影响 |
| 输出步长 | MAE/m3 | MAPE/% | R2 | RMSE/m3 |
|---|---|---|---|---|
| 全输出 | 20.71 | 4.96 | 0.99 | 53.57 |
| 最后1个月的输出 | 20.81 | 4.97 | 0.99 | 53.59 |
| 最后2个月的输出 | 23.35 | 5.14 | 0.99 | 57.47 |
| 后6个月的输出 | 24.12 | 5.28 | 0.99 | 57.53 |
| 后10个月的输出 | 24.83 | 5.31 | 0.99 | 57.62 |
注:以12个月的生产数据为输入,预测未来3个月的产量 |
4.4.3 激活函数的选择
LIU等[23]提出在基本的TCN体系结构上添加残差连接、正则化和激活函数可以提高其性能。为实现模型非线性拟合能力,在模型的第4层添加激活函数。不同激活函数下TCN模型预测精度对比显示,本文TCN模型中softsign激活函数可取得更好的预测效果(见表6 )。就本文数据集而言,由于覆盖全部输入所需因果卷积层数不多,模型不使用残差连接,同时也无需进行权重正则化来预防梯度消失的问题。但为了预防过拟合,在第3层和第5层后应用层正则化。
表6 不同激活函数下TCN模型预测结果对比 |
| 激活函数 | MAE/m3 | MAPE/% | R2 | RMSE/m3 |
|---|---|---|---|---|
| softmax | 23.63 | 5.17 | 0.99 | 57.32 |
| sigmoid | 23.49 | 5.15 | 0.99 | 55.90 |
| softsign | 20.71 | 4.96 | 0.99 | 53.57 |
| relu | 28.87 | 5.73 | 0.98 | 64.18 |
| tanh | 23.13 | 5.12 | 0.99 | 58.10 |
注:以12个月的生产数据为输入,预测未来3个月的产量 |
4.5 模型应用结果讨论
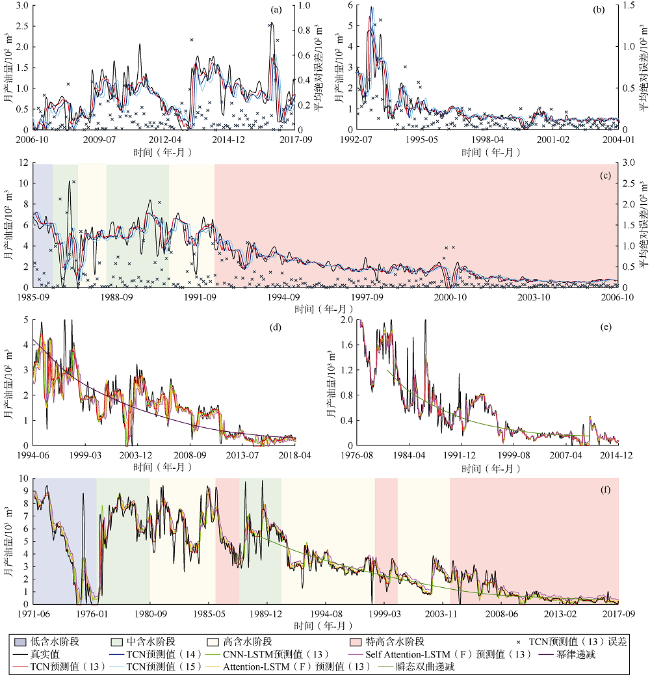
在进行油井产量预测时,通常将油井的生产历史划分为两段,使用前一段作为训练集,后一段作为测试集。本文对所建预测模型实施全生命周期测试,即用341口油井(训练集)的全部生产数据作为训练数据,对另外85口井(验证集和测试集)进行预测,直到生产结束。对测试集42口油井进行预测,随机抽取6口油井作对比分析,结果如图6 所示。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
综上所述,本文模型可以实现对油田单井月产量的高精度预测,预测精度较传统递减模型和LSTM等机器学习模型更高,更具应用价值。
5 结论
提出了基于时域卷积神经网络模型的水驱油田单井产量预测方法,实现了高效、精确的单井产量预测。采用随机森林及主成分分析等方法进行数据空缺填充和降维,保证了数据集的真实性和完备性。使用麻雀搜索算法确定模型最佳超参数,在提高工作效率的同时得到更好的模型预测精度。将单井生产历程依照含水率高低划分为低含水、中含水、高含水和特高含水4个阶段,分别建立阶段预测模型然后集成并完成单井全生命周期产量预测。分析及实例应用结果显示,相比其他11种时间序列预测模型,改进的TCN模型具有更好的预测性能。对于数据波动大且具有较明显阶段特征的产量序列预测,划分阶段、分段建模的方法可有效降低模型拟合难度、提升模型预测精度。
符号注释:
Di,j——第i口油井和第j口注水井之间的距离,m;fw——含水率,%;i——油井编号;j——注水井编号;It,i——第i口油井在t时刻受注水井影响程度,m3/m;nw,i——影响第i口油井的注水井总数;N——样本数量;k——月产量样本编号;qk——月产量真实值,m3; $\hat{q}_{k}$——月产量预测值,m3; $\overline{q}$——月产量真实值平均值,m3;t——时间(年-月);Wt,j——第j口注水井在t时刻的月注入量,m3;xo,i——第i口油井的x坐标,m;xw,j——第j口注水井的x坐标,m;yo,i——第i口油井的y坐标,m;yw,j——第j口注水井的y坐标,m。