




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
多点地质统计学中训练图像优选方法及其在地质建模中的应用
[王立鑫1  , 尹艳树
, 尹艳树1 1 , 段太忠2 , 赵磊2 , 张文彪2 ]
, 尹艳树, 冯文杰|
|


第一作者简介:王立鑫(1991-),男,湖北襄阳人,长江大学在读博士研究生,从事储集层建模方面研究。地址:湖北省武汉市蔡甸区大学路111号,长江大学地球科学学院,邮政编码:430100。 E-mail:201571323@yangtzeu.edu.cn
在前人提出的高阶兼容性优选方法的基础上,提出一种基于数据事件重复概率的训练图像优选方法。其基本思路是提取条件数据中蕴含的数据事件,统计所提取的数据事件在训练图像中的重复次数并计算其重复概率,得到数据事件的无匹配率及其重复概率方差两个统计指标,用于表征训练图像中沉积模式的多样性与平稳性,评价其与建模区井数据蕴含的地质体空间结构的匹配性。无匹配率反映训练图像内地质模式的完备性,为首选指标;重复概率方差反映训练图像内地质模式的平稳性,为辅助指标,综合以上两种指标实现了对训练图像的优选。多组理论模型测试表明,重复概率方差小、无匹配率低的训练图像为最优训练图像。运用该方法对安哥拉Plutonio油田浊积水道训练图像进行优选,结果表明所建立的地质模型与地震属性吻合度高,能够更好地刻画水道的形态特征及砂体的分布模式。
Based on the analysis of the high-order compatibility optimization method proposed by predecessors, a new training image optimization method based on data event repetition probability is proposed. The basic idea is to extract the data event contained in the condition data and calculate the number of repetitions of the extracted data events and their repetition probability in the training image to obtain two statistical indicators, unmatched ratio and repeated probability variance of data events. The two statistical indicators are used to characterize the diversity and stability of the sedimentary model in the training image and evaluate the matching of the geological volume spatial structure contained in data of the well block to be modeled. The unmatched ratio reflects the completeness of geological model in training image, which is the first choice index. The repeated probability variance reflects the stationarity index of geological model of each training image, and is an auxiliary index. Then, we can integrate the above two indexes to achieve the optimization of training image. Multiple sets of theoretical model tests show that the training image with small variance and low no-matching ratio is the optimal training image. The method is used to optimize the training image of turbidite channel in Plutonio oilfield in Angola. The geological model established by this method is in good agreement with the seismic attributes and can better reproduce the morphological characteristics of the channels and distribution pattern of sands.
针对两点地质统计建模难以真实再现复杂形态地质体的问题, Guardiano和Srivastava于1993年提出了多点地质统计学[1], 通过数据样板扫描训练图像获得数据事件来反映相应的地质模式。不同数据事件出现频率近似为空间多个点联合分布概率。多点地质统计学的思路是利用有限的地质资料, 通过沉积学分析建立训练图像, 并在条件数据约束下, 从训练图像中寻找最优的数据事件, 作为待估点模拟实现抽样的依据。因此, 在目前多点地质统计学算法本身已经较为成熟的条件下[2, 3, 4, 5, 6], 可以认为训练图像是决定模拟实现效果的关键因素之一[7, 8, 9, 10]。为了获得合理的训练图像, 学者们提出了不同的方法, 如基于目标的方法[11, 12, 13]、基于沉积过程的方法[14, 15]、基于仿沉积过程的方法[16, 17]、基于地质资料转化的方法[18, 19]等。通过以上方法可利用同一参数组合创建大量与地下地质条件相近而彼此各不相同的训练图像。尽管这些训练图像十分相似, 但其与待模拟地质体的适配性存在一定差异, 因此, 优选出最适用于模拟目标的训练图像显得十分重要, 并引起了广泛的关注[8, 9, 20, 21]。
截至目前, 用于训练图像优选的专用算法主要包括基于变差函数的优选方法、基于条件概率的优选方法[8, 9, 20]以及基于相似距离的优选方法[21]3类。基于变差函数的优选方法仅能对比二阶空间结构特征, 无法对更高阶地质统计特征进行定量化分析[21]。Ortiz及Deutsch提出了一种通过高阶地质统计信息对训练图像进行排序的方法[20], Boisvert提出了基于数据事件分布和多点条件概率方程的训练图像优选方法[8]; 但这两种方法仅沿井轨迹提取一维数据事件进行分析, 未考虑到多井条件下更高阶数据事件的复杂性, 因而无法有效地获取三维空间内不同位置的高阶地质统计信息, 难以满足训练图像优选中对多井联合高阶数据事件分析的需求。Pé rez提出了一种基于数据事件高阶兼容性的训练图像优选方法[9]; 该方法将满足相同条件点数的数据事件归为一类, 计算数据事件在训练图像中的兼容性, 进而优选训练图像; 但是该方法在提取数据事件过程中过于强调已知点数量的统一, 造成所提取的数据事件的三维结构各不相同, 导致其无法准确揭示训练图像与条件数据的真实匹配度。冯文杰提出了一种基于数据事件相似度计算与排序的优选方法[21]; 该方法计算模拟网格中每个网格节点对应数据事件与训练图像中具有同样空间结构数据事件的相似度, 并通过相似度属性体的均值与方差优选训练图像; 由于强调数据事件空间结构的匹配度, 该方法在条件点较少时, 获取用于相似度计算的数据事件有限, 优选结果的可靠性降低, 同时该方法需要多次扫描训练图像计算数据事件的相似度, 造成优选过程耗时较长。
在前人研究的基础上, 本文在Pé rez所提的高阶兼容性优选方法基础上提出了一种改进的优选方法, 即数据事件重复概率统计法, 包括数据事件的无匹配率及其重复概率方差。数据事件无匹配率越低, 重复概率方差越小, 训练图像与研究区越匹配。理论模型和实际模型测试表明, 新方法较好地实现了训练图像排序和优选, 这一研究为多点地质统计建模中训练图像优选提供了新手段, 能够更好地服务于多点地质统计建模。
Pé rez提出的高阶兼容性的优选方法[9], 通过数据样板扫描训练图像获得数据事件重复次数Ri, j, 然后计算数据事件重复次数在各训练图像中的相对频率Pi, j, 对每个训练图像中的数据事件的相对频率进行归一化处理, 得到各训练图像的相对兼容性Cj。其中, 相对频率Pi, j指第i个数据事件在第j个训练图像中的重复次数占该数据事件在t个训练图像中重复总次数的比例, 即:
${{P}_{i, j}}=\frac{{{R}_{i, j}}}{\sum\nolimits_{j=1}^{t}{{{R}_{i, j}}}}\text{ }$ (1)
相对兼容性Cj指第j个训练图像中n个数据事件的相对频率总和占n个数据事件在t个训练图像相对频率总和的比例, 即:
${{C}_{j}}=\frac{\sum\nolimits_{i=1}^{n}{{{P}_{i, j}}}}{\sum\nolimits_{j=1}^{t}{\sum\nolimits_{i=1}^{n}{{{P}_{i, j}}}}}$ (2)
绝对兼容性Mj指第i个数据事件在第j个训练图像中是否出现, 如果出现则Yi, j为1, 否则Yi, j记为0, 然后计算此训练图像中包含出现数据事件的占比:
${{M}_{j}}=\frac{\sum\nolimits_{i=1}^{n}{{{Y}_{i, j}}}}{n}\text{ }$ (3)
该方法认为, 兼容性越高, 训练图像越匹配。但由于其仅考虑条件数据点数量, 而没有考虑不同数据点空间分布差异, 从而导致训练图像与真实数据事件的兼容性统计出现误差, 不能实现训练图像的准确优选。
数据事件重复概率旨在体现训练图像内特定数据事件的分布特征。对t个候选的训练图像, 用指定的模板扫描条件数据得到n个数据事件的集合CE, 在第j个训练图像中搜索第i个数据事件CEi出现的次数, 记作Ri, j; 然后计算数据事件在各训练图像中的分布特征, 即数据事件重复概率方差σ j及数据事件无匹配率UNPj(以下简称重复概率方差及无匹配率)。
单个数据事件的重复次数Ri, j在训练图像全部数据事件重复次数的占比即为数据事件重复概率, 即:
$P{{T}_{i, j}}=\frac{{{R}_{i, j}}}{\sum\nolimits_{i=1}^{n}{{{R}_{i, j}}}}$ (4)
重复概率方差σ j即统计训练图像中数据事件重复概率的方差, 即:
${{\sigma }_{j}}=\frac{\sum\nolimits_{i=1}^{n}{\left( P{{T}_{i, j}}-\overline{P{{T}_{j}}} \right)}}{n}$ (5)
其中$\overline{P{{T}_{j}}}$为第j个训练图像中数据事件重复概率的均值。
训练图像中搜索到匹配的数据事件, 则指示值Ui, j记为1, 否则记为0。然后计算无匹配数据事件的占比, 即数据事件无匹配率UNPj:
$UN{{P}_{j}}=1-\frac{\sum\nolimits_{i=1}^{n}{{{U}_{i, j}}}}{n}$ (6)
无匹配率低表明训练图像与实际区匹配的地质模式丰富, 重复概率方差小说明训练图像与实际区匹配的地质模式分布稳定。因此, 一个较优的训练图像具有更低的无匹配率与更小的重复概率方差。
对已建立的研究区网格模型, 选择合适的搜索模板, 利用条件数据事件扫描训练图像, 获得完全匹配的模式, 该数据事件的重复次数增加, 直到完成所有数据事件的搜索。返回与条件数据事件完全匹配的重复次数Ri, j, 计算数据事件重复概率PTi, j, 根据数据事件重复概率PTi, j计算重复概率方差σ j及无匹配率UNPj, 利用重复概率方差及无匹配率完成训练图像的优选。具体步骤如下:①确定搜索样板, 寻找数据事件; ②选中一个数据事件, 扫描训练图像, 寻找与数据事件匹配的模式, 如果数据事件条件点在训练图像中找到完全匹配, 该数据事件重复次数Ri, j增加1, 直到此训练图像搜索完毕; ③转到下一数据事件, 重复步骤②, 直至全部数据事件搜索完毕; ④选择下一个训练图像, 重复步骤②③, 直至所有训练图像扫描完成; ⑤计算数据事件重复概率PTi, j; ⑥计算重复概率方差σ j以及无匹配率UNPj, 完成训练图像优选和排序。
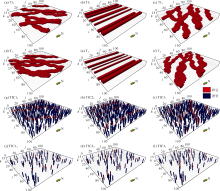
三维测试网格数为100× 100× 15, 单网格大小为10 m× 10 m× 0.5 m, 建立3个不同规格的相模型TI1、TI2、TI3(见图1a— 1c), 并随机产生了500口井获得的条件数据TIC11、TIC21、TIC31(见图1g— 1i), 条件点占比为5%。3个相模型中TI1与TI3同为河流相模式, 仅物源方向不同; TI2为简单的条带模式, 垂向上无明显渐变特征。对应这3种相模型建立了3个训练图像T1、T2、T3(见图1d— 1f), 预期通过各自的条件数据优选出与原型接近的训练图像。
 | 图1 条件数据与训练图像(a— c与d— f为泥岩镂空显示, 单网格大小为10 m× 10 m× 0.5 m) |
针对各组条件数据, 分别采用高阶兼容性方法和数据事件重复概率统计法筛选训练图像。设置搜索模板7× 7× 5, 据高阶兼容性方法, 统计搜索到1、2、3、5、7、9、10、15、20、25个条件点时的数据事件重复次数, 得到对应的绝对兼容性(见图2a— 2c)与相对兼容性(见图2d— 2f)。利用改进的方法, 对满足15个条件点的数据事件, 统计其无匹配率及重复概率方差(见图3)。测试结果显示两种方法的优选结果均符合预期, 能够服务于训练图像的优选。
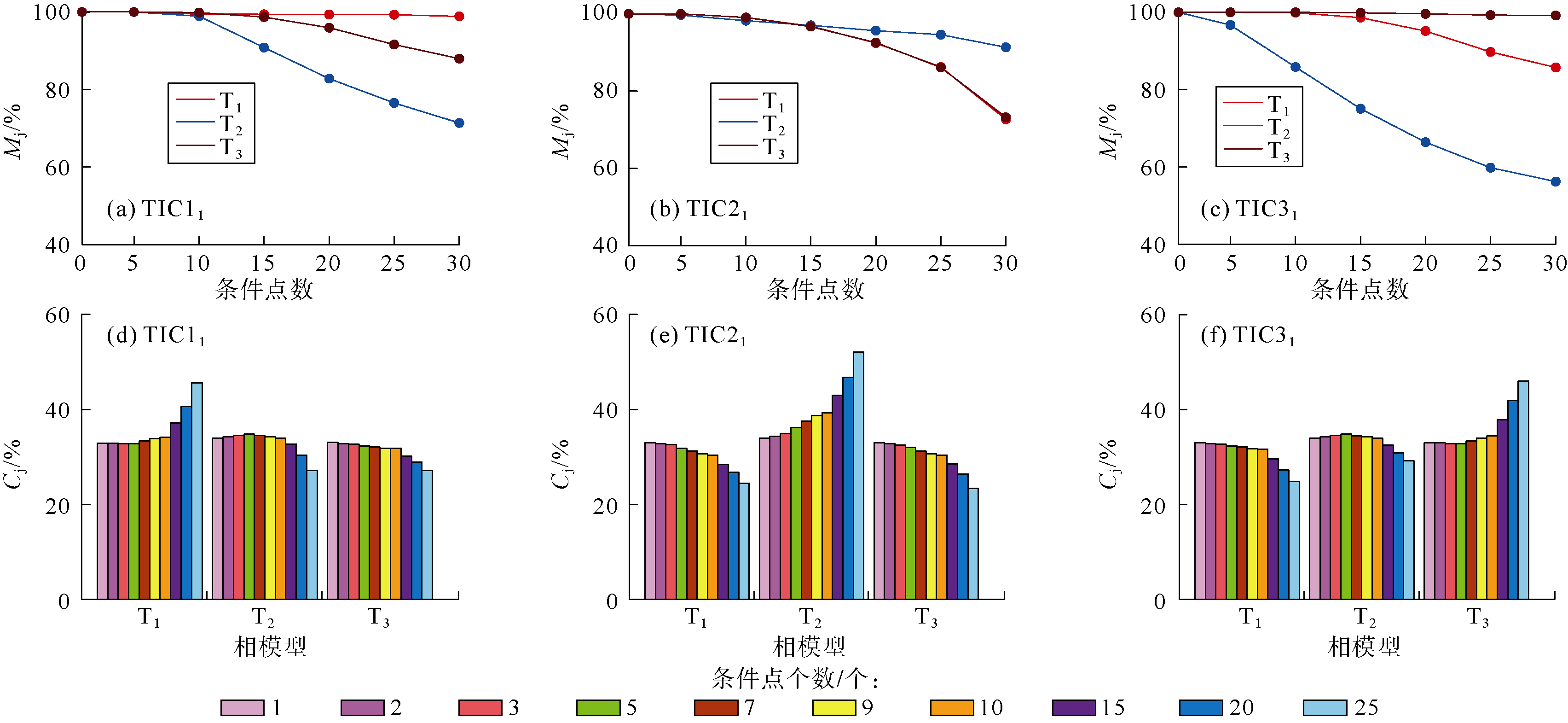 | 图2 高阶兼容性特征 |
 | 图3 数据事件重复概率统计特征 |
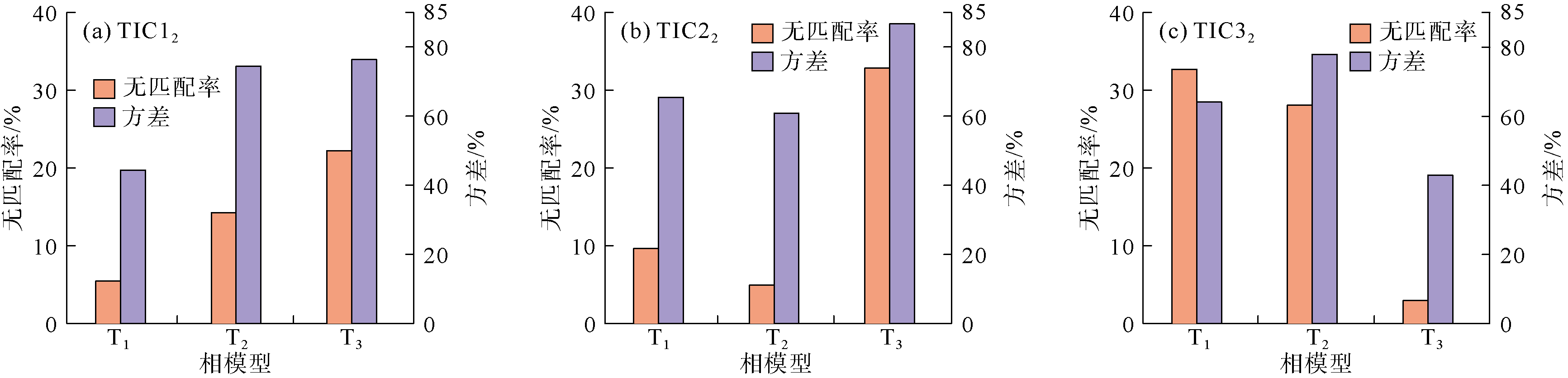
在实际油藏中条件数据点相对于研究区网格数据是非常少的, 故在原有测试模型的基础上将条件数据占比减少至1%(见图1j— 1l)。在条件数据稀少的情况下, 评价两种方法优选效果及其适用性。结果表明, 抽稀后高阶兼容性方法无法有效地优选出匹配的训练图像(见图4), 其中条件点TIC12优选出训练图像T2, 与预期结果相悖(见图4a), 条件点TIC32测试仅在条件点数大于15个时能够明显区分, 而采用新方法对满足9个条件点的数据事件统计, 依然能够实现有效优选(见图5); 显然改进后的方法更具优势, 能够应用于实际油藏训练图像的优选。
 | 图4 训练图像对3种条件数据的相兼容性 |
 | 图5 条件数据占比1%时数据事件重复概率统计特征 |
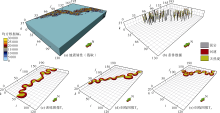
西非安哥拉Plutonio油田位于西非下刚果— 刚果扇盆地南端、现今大陆斜坡的中下部位置, 水深为1 000~1 500 m。主力含油层系为第三系渐新统O73砂层组, 前人研究认为该区O73砂层组为典型的深水浊积水道沉积[22]。该区主要发育水道和天然堤微相类型, 其中水道砂为主要储集层。该区构造变形强烈, 受后期盐底辟活动影响, 导致砂体结构复杂。本次研究层位为浅层另一套浊积水道砂体沉积, 构造稳定, 形态保存完整, 地震资料分辨率高, 浅层与深层水道具有相似的沉积环境, 故利用浅层高分辨地震资料提取水道形态参数以指导训练图像的建立。根据浅层地震均方根振幅属性地层切片, 结合工区测井资料对浊积水道定量化解释, 推测浊积水道宽度为850~2 500 m, 其中单一水道砂体厚度为8~23 m, 宽度为91~305 m。研究区目的层段各小层内浊积水道具有不同的方向, 根据获取的多个宽度、厚度、弯曲度及流向等参数, 采用改进的Alluvsim算法[23], 建立了3个与目的层段浊积水道相近的训练图像, 网格数为120× 190× 20(见图6), 单网格大小为20 m× 20 m× 0.75 m。
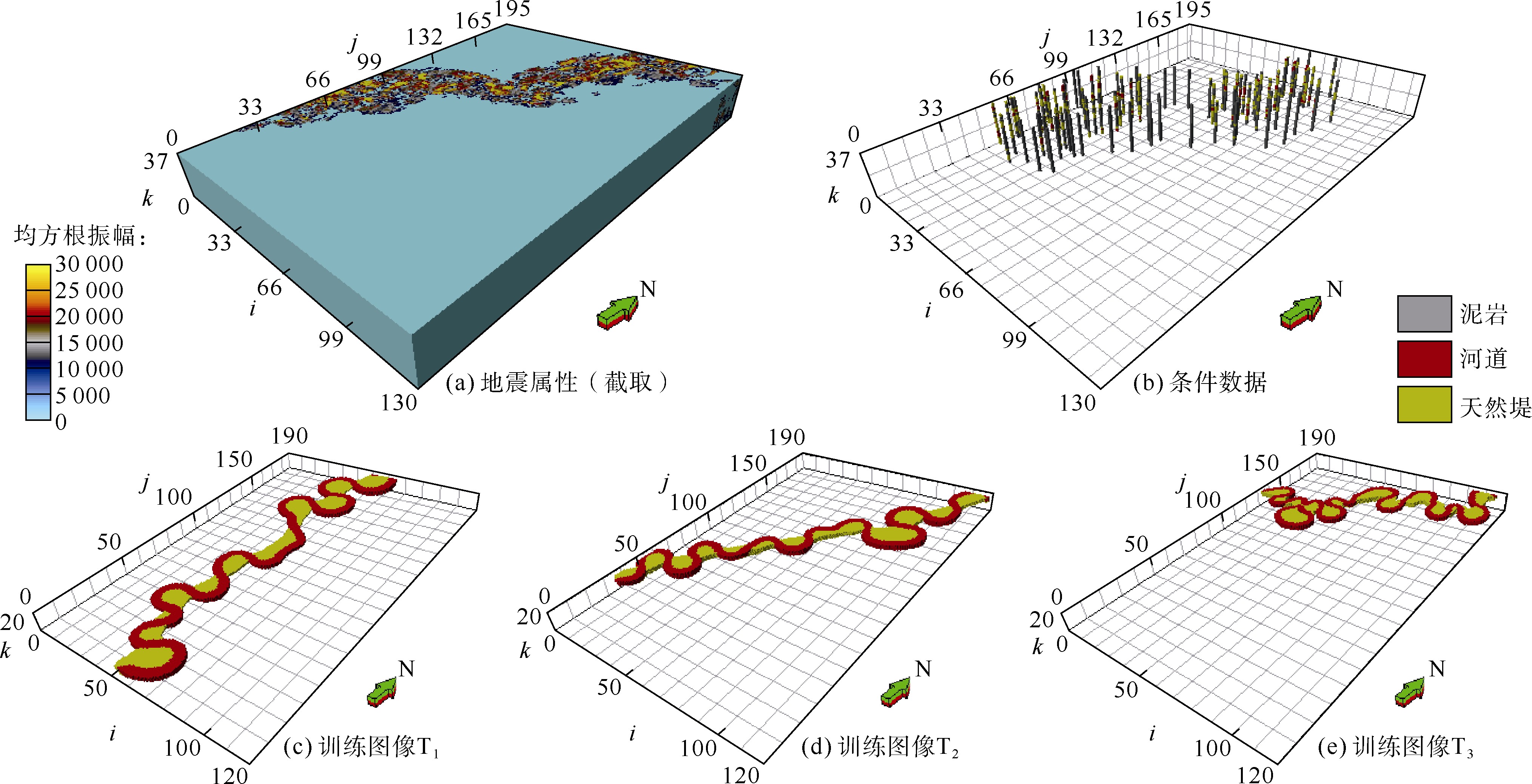 | 图6 研究区测试数据(图c— e为泥岩镂空显示, 单网格大小为20 m× 20 m× 0.75 m) |
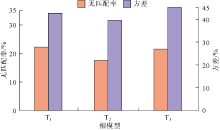
针对目的层段小层内浊积水道建模(见图6a), 研究区网格模型网格数为130× 195× 37, 单网格大小为20 m× 20 m× 0.75 m, 采用本文提出的新方法对已获取的多个训练图像进行优选, 设置搜索模板为11× 11× 3, 对满足6个条件点的数据事件进行重复概率统计分析, 得到重复概率方差及无匹配率(见图7), 其中训练图像T2的数据事件重复概率方差及无匹配率最低, 表明训练图像T2是最优的。
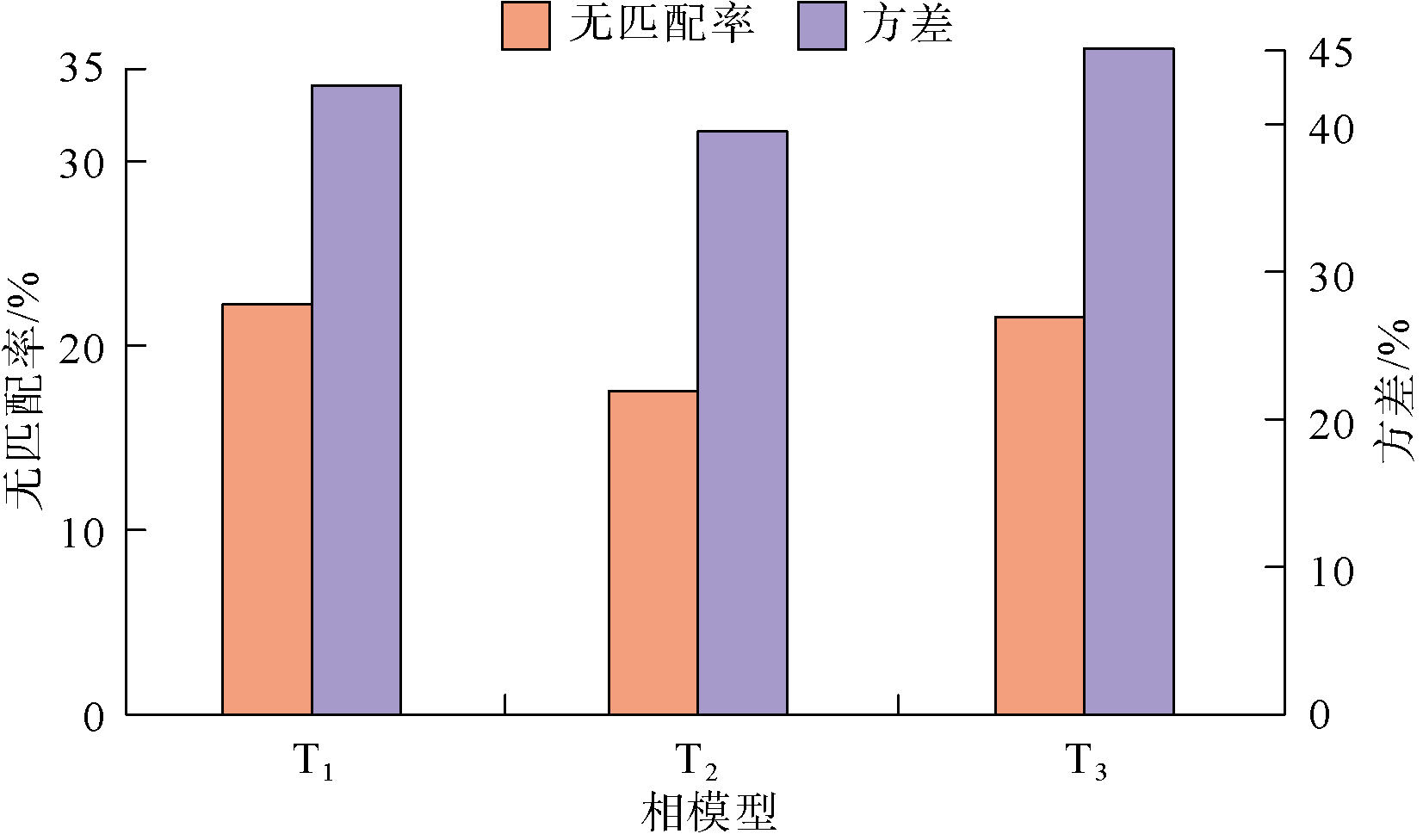 | 图7 数据事件重复概率统计特征 |
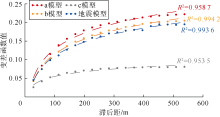
采用多点地质统计SNESIM方法在相同的参数环境下建模[24], 获得了由3个不同训练图像产生的地质模型(见图8)。计算3个地质模型的变差函数, 并与实际地震属性体的变差函数进行比较(见图9), a模型的变差函数与实际地震变差函数差距最大, 其次是c模型的, 而b模型的变差函数与地震属性体的变差函数最接近, 表明b模型的岩相连续性与地震属性的连续性接近, 即训练图像T2的模拟结果更加符合实际地质特征, 与优选结果一致。改进的方法能够服务于实际油藏训练图像优选与多点地质统计建模。
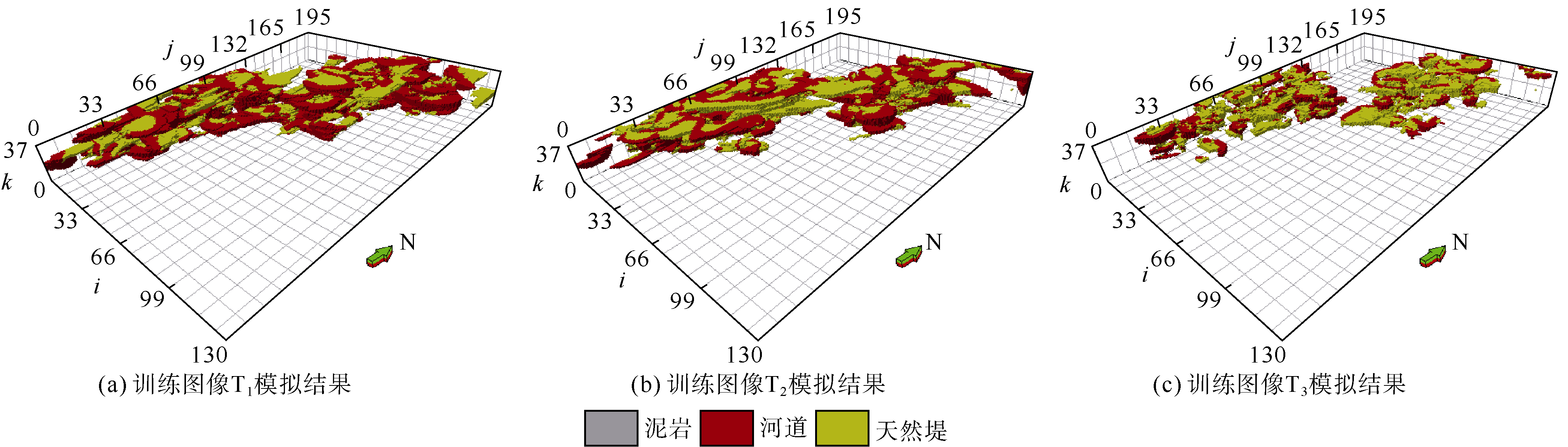 | 图8 多点SNESIM方法实现(泥岩镂空显示) |
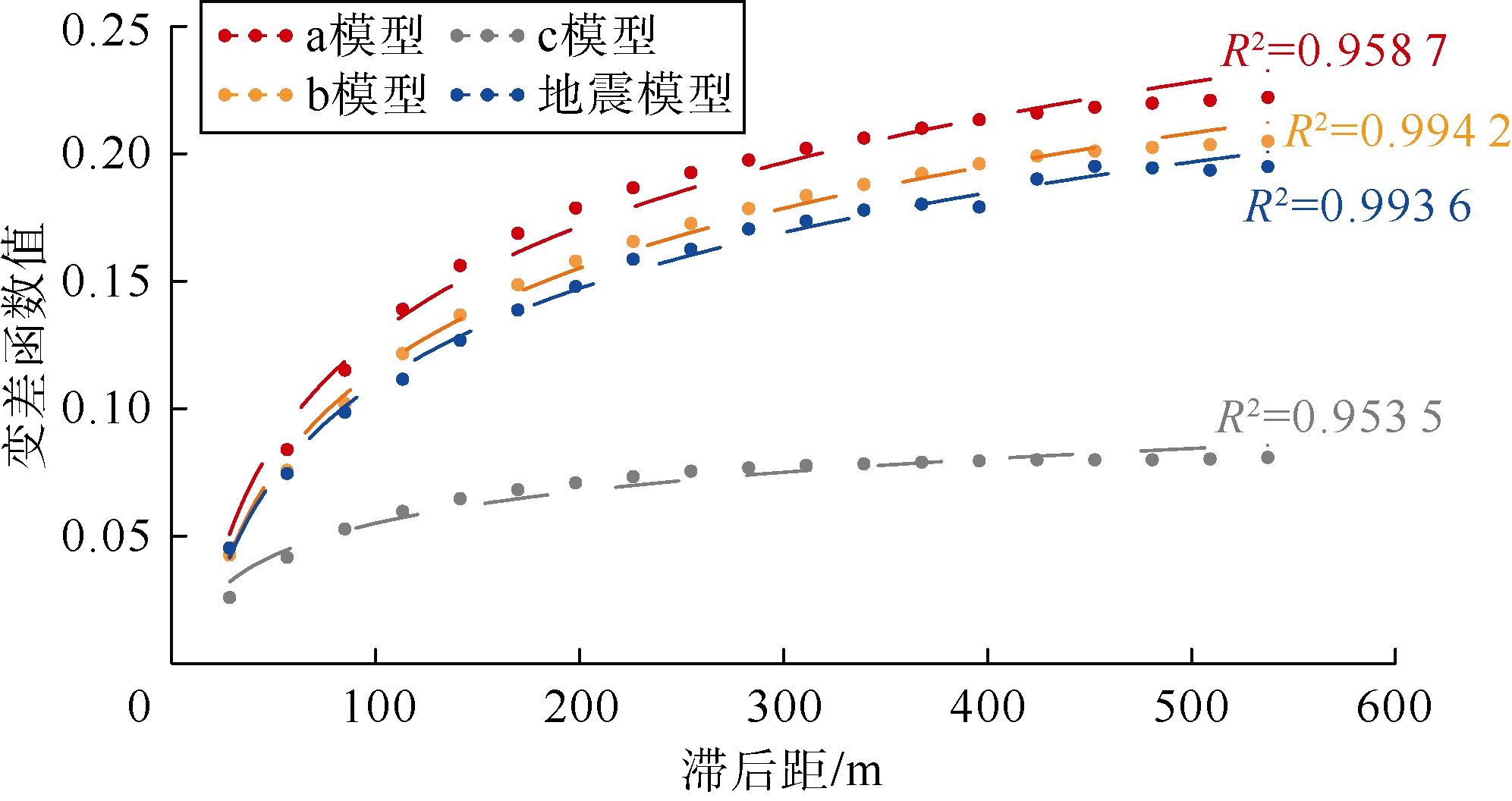 | 图9 各模型的变差函数拟合结果 a模型— 训练图像T1模拟结果; b模型— 训练图像T2模拟结果; c模型— 训练图像T3模拟结果 |
数据事件重复概率从数据事件的空间差异出发, 以数据事件的稳定性作为训练图像优选的指标, 通过重复概率方差对模式的稳定性进行评价, 通过无匹配率对模式的多样性进行评价, 能够更加全面地优选训练图像。一个较优的训练图像具有稳定的沉积模式分布, 且重复概率方差越小, 对应训练图像中地质模式的稳定性越高; 无匹配率越低, 对应训练图像中地质模式的完备性越高。
理论模型测试表明, 在条件数据点较少的情况下, 数据事件重复概率指标能够有效优选出最优训练图像。通过西非安哥拉Plutonio油田浊积水道训练图像优选及应用, 根据研究区浅层高分辨率地震提取的水道形态特征参数建立了多种训练图像, 该方法能有效地优选出与目的层段最适配的训练图像, 采用优选出的训练图像所建立的地质模型与地震属性有较好的对应关系, 提高了多点地质统计建模的准确性。
符号注释:
Cj— — 第j个训练图像的相对兼容性; Mj— — 第j个训练图像的绝对兼容性; n— — 条件数据事件总数; Pi, j— — 数据事件重复次数在各训练图像中的相对频率; PTi, j— — 第i个数据事件在第j个训练图像中的重复概率; $\overline{P{{T}_{j}}}$ — — 第j个训练图像中数据事件重复概率的均值; R— — 复相关系数; Ri, j— — 第j个训练图像中第i个数据事件的重复次数; t— — 参与优选的训练图像数量; UNPj— — 第j个训练图像中数据事件的无匹配率; Ui, j— — 第i个数据事件在第j个训练图像中匹配的指示值; Yi, j— — 第i个数据事件在第j个训练图像中出现的指示值; σ j— — 第j个训练图像中数据事件重复概率的方差。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|